CS224w 图机器学习笔记
课程主页: https://web.stanford.edu/class/cs224w 笔记原文: https://archives.leni.sh/stanford/CS224w.pdf or CS224w Notes
0 Introduction¶
0.1 为什么选择图?¶
图是一种用于描述和分析具有关系和交互作用的实体的通用语言。其应用场景包括:
- 分子:顶点是原子,边是化学键
- 事件图
- 计算机网络
- 疾病传播路径
- 代码依赖图
复杂领域具有丰富的结构化关系,可以通过关系图来表示。通过显式地建模这些关系,我们可以在更低的模型容量下实现更好的性能。现代机器学习工具处理的是张量,例如图像(二维)、文本/语音(一维)。现代深度学习工具是为简单的序列和网格设计的,并非所有事物都可以表示为序列或网格。那么,我们如何开发出更广泛适用的神经网络呢?答案是使用图,图可以连接一切。
- 图神经网络是 ICLR 2022 的第三大热门关键词。
- 图学习也非常困难,因为图的结构复杂且不规则。
- 图学习也与表示学习有关。在某些情况下,可能可以为图中的每个节点学习一个 d 维嵌入(embedding),使得相似的节点具有更接近的嵌入。
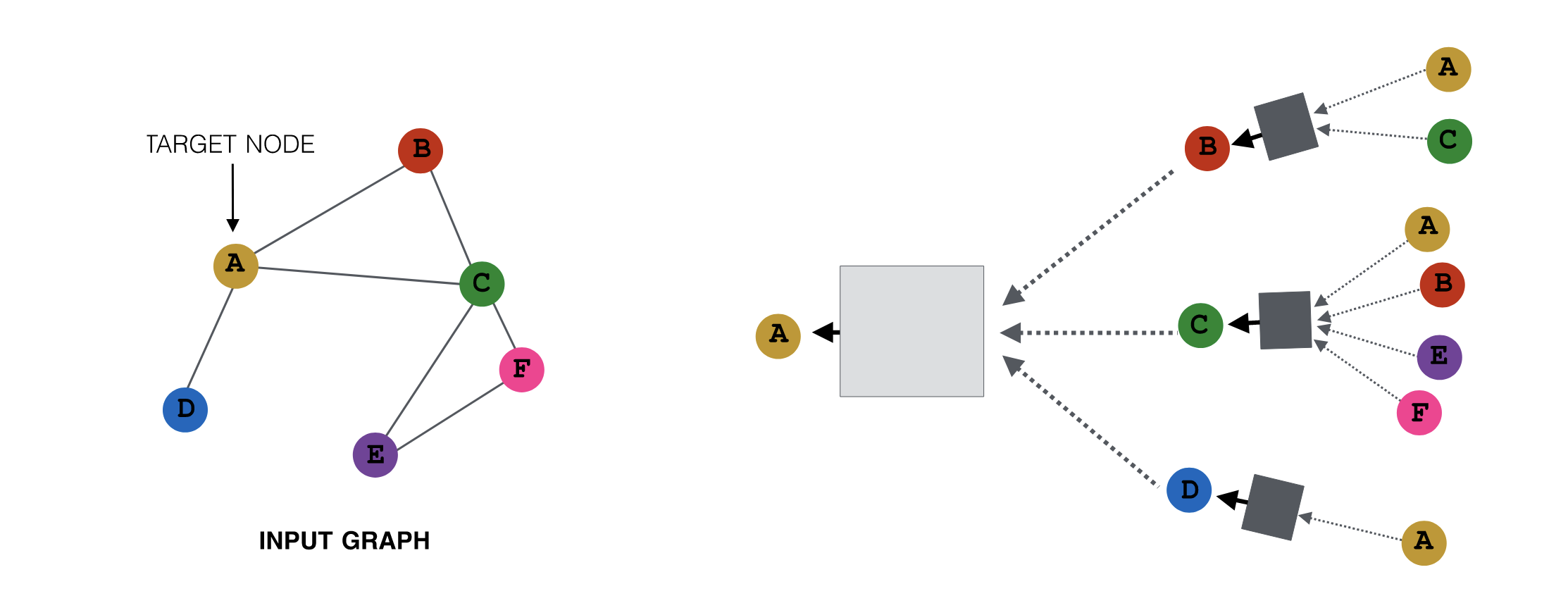 Figure0.1 当机器学习模型应用于图时, 每个节点都定义了自己的计算图
Figure0.1 当机器学习模型应用于图时, 每个节点都定义了自己的计算图
可以针对图数据执行多种任务:
- 节点级预测:用于表征节点在网络中的结构和位置。例如,在蛋白质折叠中,每个原子是一个节点,任务是预测节点的坐标。
- 边/链接级预测:预测一对节点的属性。这可以是寻找缺失的链接,也可以是随着时间推移发现新的链接。例如,基于图的推荐系统和药物副作用预测。
- 图级预测:对整个子图或图进行预测。例如,交通预测、药物发现、物理模拟和天气预报。
 不同级别的图任务
不同级别的图任务
0.2 图嵌入的选择¶
图包含以下几种组成部分:
- 对象 N:节点Nodes、顶点vertices
- 交互 E:边Edges、链接Links
- 系统 G(N, E):网络Networks、图graphs
在某些情况下,图有统一的表示形式,而在某些情况下则没有。表示形式的选择决定了可以从图中提取哪些信息。图还可能具有其他属性:
- 无向/有向边
- 允许/不允许自环
- 允许/不允许多图(节点之间有多条边)
- 异构图heterogeneous graph:图 \(G = (V, E, T, R, τ, ϕ)\),其中节点有类型 \(τ(v) : T\),边有类型 \(ϕ(e) : R\)。
- 许多图是异构的。例如,药物-蛋白质相互作用图是异构的。
- 二分图:例如作者-论文图、演员-电影图
大多数真实世界的网络是稀疏的。邻接矩阵是一个稀疏矩阵,其中大部分是 0。矩阵的密度 (E/N²) 对于 WWW 是 1.51×10⁻⁵,对于 MSN IM 是 2.27×10⁻⁸。
1 传统机器学习中的图¶
在传统的机器学习流程中,例如逻辑回归、随机森林和神经网络,模型首先在图的特征上进行训练,然后可以应用于新的图。使用有效的图特征是实现良好模型性能的关键 -> 特征工程。
为了简化,本节我们关注无向图。
1.1 节点级特征¶
节点级任务的一个简单例子是基于少量样本的节点分类(如图所示)。
 在仅提供较少标签(样本)的情况下, 对图节点进行分类
在仅提供较少标签(样本)的情况下, 对图节点进行分类
几种不同的度量可以表征节点在图中的结构和位置:节点度, 节点中心度, 聚类系数
节点度:邻居的数量。
节点中心度¶
节点中心性:衡量节点在图中“重要性”的指标。存在几种不同类型的中心性。
- 特征向量中心性:如果一个节点被重要的邻居节点包围,那么这个节点就是重要的。我们定义节点 v 的中心性为邻居节点的中心性。这导致了一组 |N| 的线性方程: \(c_{v} := \frac 1λ\sum_{u∈N(v)}c_{u}\Longleftrightarrow λ\mathbf c=\mathbf A\mathbf c\) 其中,λ 是归一化常数,A 是图的邻接矩阵, \(N(v)\) 是节点 v 的所有邻节点集合。根据佩龙-弗罗贝尼乌斯Perron-Frobeniu定理,最大特征值 λmax 总是正的且唯一,其对应的特征向量可用于中心性计算。当 λ 是第二大的特征值时,\(c_{v}\) 有不同的含义。
太好了, 是线性代数, 已经全忘了
- 介数中心性:如果一个节点是“把关者”,即它位于许多其他节点之间的最短路径上,那么这个节点就是重要的。 \(c_v:=\sum_{s\neq v\neq t}\frac{\text{包含 }v\text{ 的 }s,t\text{ 之间的最短路径数量}}{\text{所有 }s,t\text{ 之间的最短路径数量}}\)在社交网络中,这一指标非常重要。
- 接近中心性Closeness centrality: \(c_v:=\frac{1}{\sum_{u\neq v}v,u\text{ 之间的最短路径长度}}\)
聚类系数与图元Graphlet¶
聚类系数Clustering coefficient:衡量节点 v 的邻居节点之间的连接紧密程度 \(e_v:=\frac{|\{N(v)\text{之间的边}\}|}{\binom{k_{v}}{2}}\in[0,1]\)
- 注: 组合数\(\binom{N}{k}=C(N,k)=C_{N}^k=\frac{N!}{k!(N-k)!}\)
- 社交网络中存在大量的聚类现象。
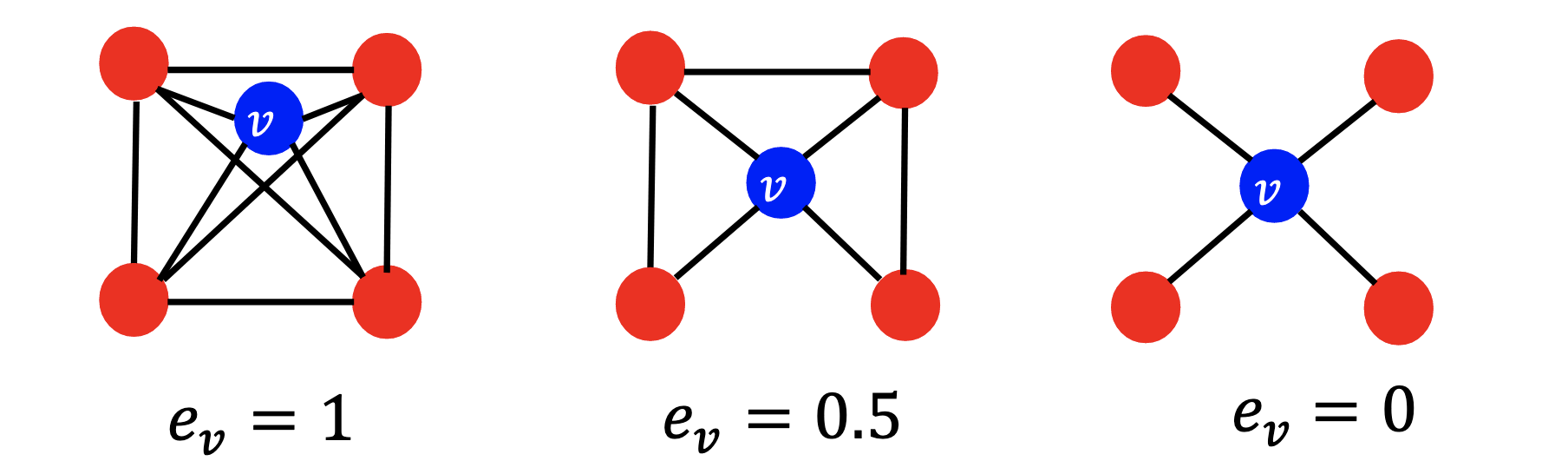 一些聚类系数的例子
一些聚类系数的例子
聚类系数计算了 ego 网络(由 \(\{v\}∪N(v)\) 形成的网络,其中 v 是 ego)中的三角形数量。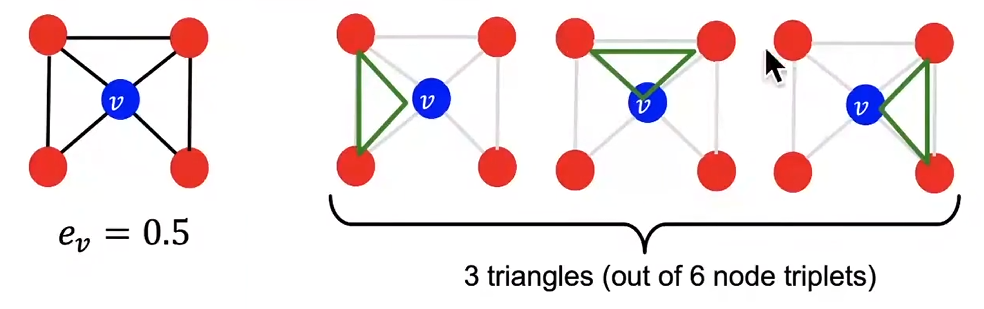
注: Ego网络(Ego Network) 是社会网络分析中的一个重要概念,它指的是围绕一个中心节点(称为“ego”)构建的子网络,包括该中心节点及其直接连接的所有邻居节点(称为“alters”),以及这些邻居节点之间的连接。
我们可以将上述内容推广为计算图元(graphlets)。
图元(Graphlets) 是描述节点 u 的邻域网络结构的小型子图。具体来说,它们是Rooted、连通的Connected、导出的induced、非同构的non-isomorphic子图。
- Rooted: 指graphlet需要考虑它的根节点(如3-node graphlets中所示, 链式的有两种graphlets)
- 导出子图/诱导子图induced subgraph是指, 由较大图顶点的一个子集和该图中两端均在该子集的所有边的集合组成的图。
- 如果两个图具有相同的拓扑结构,则它们是同构isomorphic的。
- 对于5个节点, 可以提取出73种graphlet
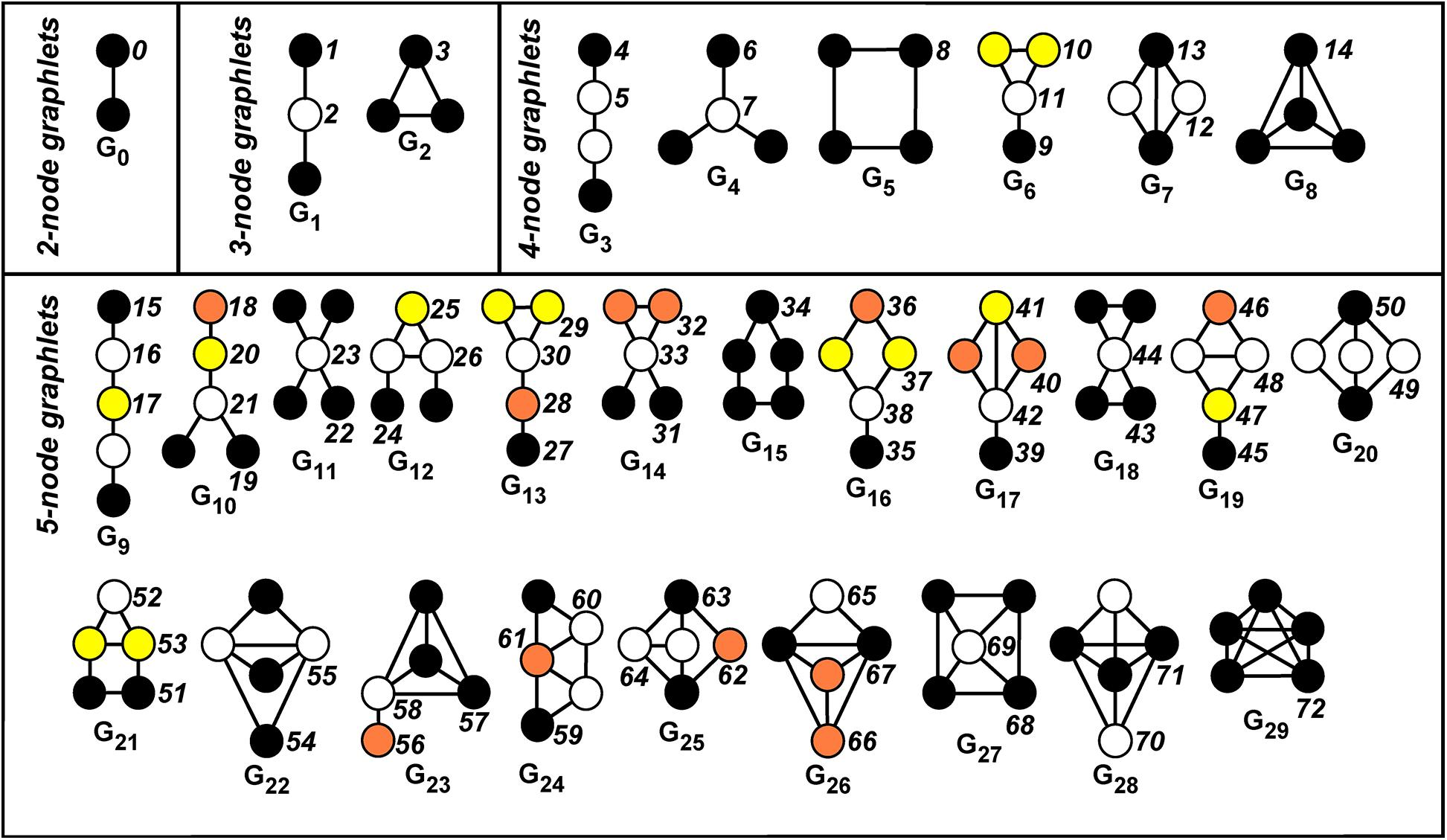
(节点的)图元度向量(Graphlet Degree Vector, GDV): 当我们考虑大小为2~5个节点的图元时,我们得到一个包含73个元素(即从2到5个顶点的图元数量)的向量,用于描述节点邻域的拓扑结构。这个向量被称为节点的图元度向量(Graphlet Degree Vector, GDV)。
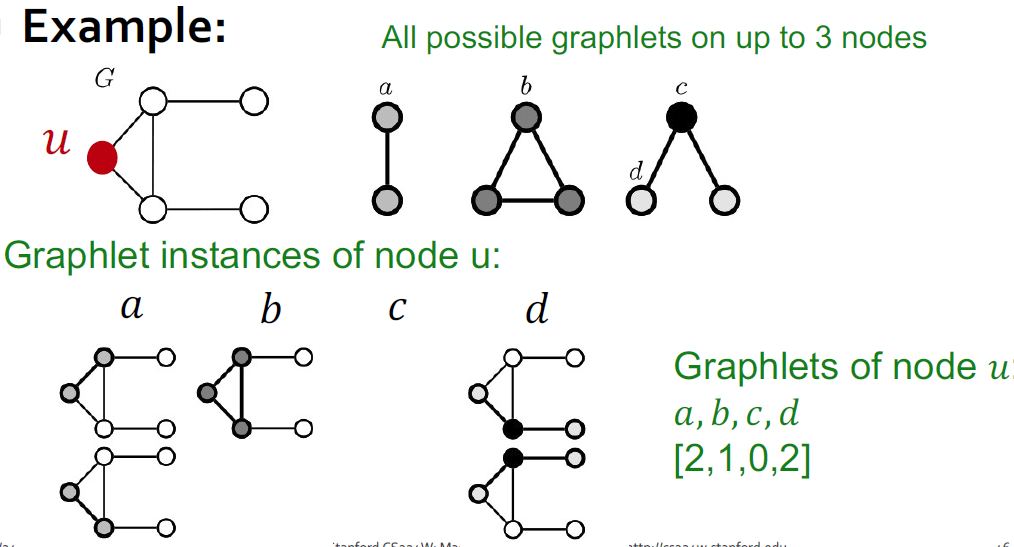 GDV例
GDV例
- 借助GDV, 可以更精细的比较两个图的局部结构相似性
到目前为止我们讨论的特征捕捉了图的局部拓扑属性,但无法在全局范围内区分点。
1.2 链接级特征¶
链接级预测有两种表述方式:
- 随机缺失的链接:从图中随机移除一组链接,然后尝试预测它们。
- 例如,药物相互作用。
- 随时间变化的链接:给定一个由时间\(t_{0}'\)之前(时间段)的边定义的图 \(G[t_{0},t_{0}']\),输出一个排名的链接列表 L,预测在时间 \(G[t_{1},t_{1}']\) 中可能出现的边。
- 如已知当前的好友网络, 预测接下来哪些人最有可能加为好友
- 评估方法:设 \(n=∣E_{new}∣\) 为测试期间(\([t_{1},t_{1}']\) )新出现的边的数量。
- 方法:对于每一对节点 x,y,计算一个分数 c(x,y),并将排名最高的 n 个元素预测为链接。
几种用于局部邻域重叠的度量方法如下:
- 共同邻居: \(c(v_{1},v_{2}):=∣N(v_1)∩N(v_2)∣\)
- 杰卡德系数Jaccard's coefficient:\(c(u,v):=\frac{∣N(v_1)∪N(v_2)∣}{∣N(v_1)∩N(v_2)∣}\)
- 阿达米克-阿达尔指数Adamic-Adar index: \(c(u,v):=\sum_{u∈N(v_1)∩N(v_2)}\frac{1}{log(k_{u})}\)
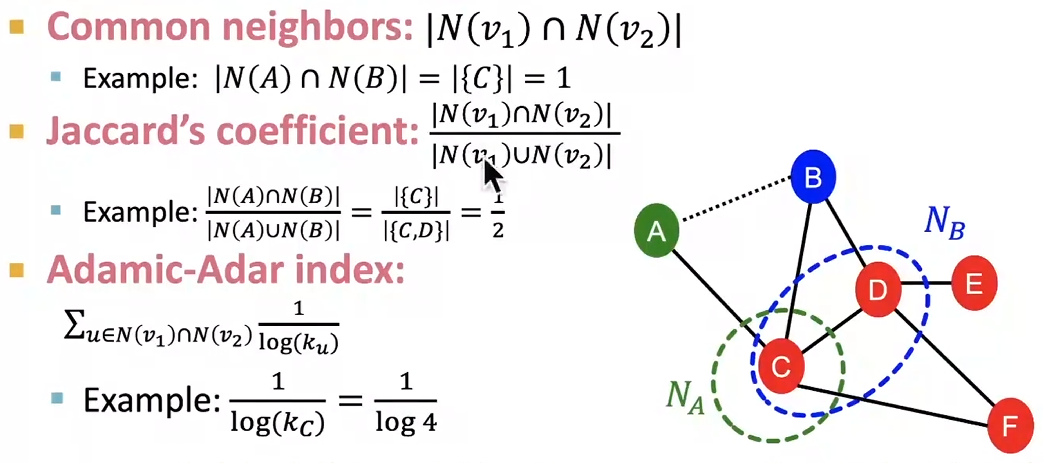
上述三种指标的问题是,如果 u,v 没有共享邻居,它们的值总是为 0。
- Katz 指数:\(c(u, v) := | \{\text{节点 } u \text{ 和 } v \text{ 之间所有长度的所有路径}\} |\)
- 这可以通过邻接矩阵的幂来计算。计算顶点之间长度为n的所有路径的矩阵是 \(\mathbf A^n\),因此 Katz 指数可以通过以下公式计算:\(\mathbf C := \sum_{i=1}^{\infty} \beta^i \mathbf A^i = (I - \beta \mathbf A)^{-1} - \mathbf I\)其中,\(\beta < 1\) 是一个衰减因子,用于防止 C 发散至正无穷大。
- 对于有向图也有类似的定义。
解释¶
-
定义:
- c(u, v) 表示节点 u 和节点 v 之间所有长度的所有路径的数量。
-
计算方法:
- 使用邻接矩阵 A 的幂次来计算路径数量。具体来说, A^n 矩阵中的元素 (A^n)_{uv} 表示从节点 u 到节点 v 长度为 n 的路径数目。
- 所有长度路径的总和可以通过无限级数 \sum_{i=1}^{\infty} \beta^i A^i 来表示,其中 \beta 是一个衰减因子。
-
衰减因子 \beta:
- \beta 必须小于 1,以确保上述级数收敛,从而防止 C 发散到正无穷大。衰减因子的作用是给较长路径赋予较小的权重,因为较长路径通常不如较短路径重要。
-
公式推导:
- 上述级数可以简化为矩阵形式: C = (I - \beta A)^{-1} - I ,其中 I 是单位矩阵。
- 这个公式通过矩阵求逆操作计算了所有长度路径的加权和,减去单位矩阵 I 是为了去除路径长度为零的情况(即节点与自身的直接连接)。
-
有向图的应用:
- 类似的定义也适用于有向图。在这种情况下,邻接矩阵 A 中的元素 A_{ij} 表示从节点 i 到节点 j 是否存在一条有向边。其余计算过程与无向图相同。
1.3 图核方法¶
图核方法的目标是为整个图创建一个特征向量。核方法广泛用于传统机器学习中的图级预测任务。与其设计特征向量,不如设计核函数:
- \(K(G,G')∈R\)
- 核矩阵 \(K=[K(G,G')]_{G,G'}\) 必须始终是半正定的。
- 存在一个特征表示 ϕ,使得 \(K(G,G')=ϕ(G)⋅ϕ(G')\),这甚至可以是无限维的。
我们可以使用“词袋”(Bag-of-Words, BOW)来表示图。回想在自然语言处理中,BOW 仅使用单词计数作为文档的特征向量,而不考虑顺序。我们将节点视为“单词”。
图级图元特征 Graph-Level Graphlet features 计算图中不同图元的数量。这里的图元与节点级特征中的定义略有不同,它们不是根节点,也不需要是连通的。这一定义的局限性在于,计算图元是昂贵的。通过枚举计算大小为 k 的图元在大小为 n 的图中需要 \(O(n^k)\) 时间,因为子图同构测试成本高昂。如果图的节点度数有界,则时间可以压缩到 \(O(nd^{k−1})\)。
到目前为止,我们只考虑了与图结构相关的特征,而没有考虑节点及其邻居的属性。
2 节点嵌入 Node Embeddings¶
表示学习避免了每次都需要进行特征工程。目标是将单个节点或整个图映射到向量中,即嵌入embedding。 在节点嵌入中,我们希望嵌入具有以下属性:
- 嵌入之间的相似性表示节点在网络中的相似性
- 例如,距离更近的节点可以被认为是相似的
- 编码网络信息
- 对下游任务可能有用, 但是与下游任务无关
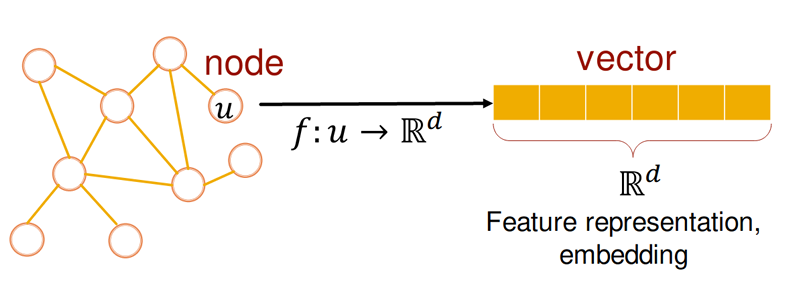 图节点嵌入: 将每个节点映射为一个向量
图节点嵌入: 将每个节点映射为一个向量
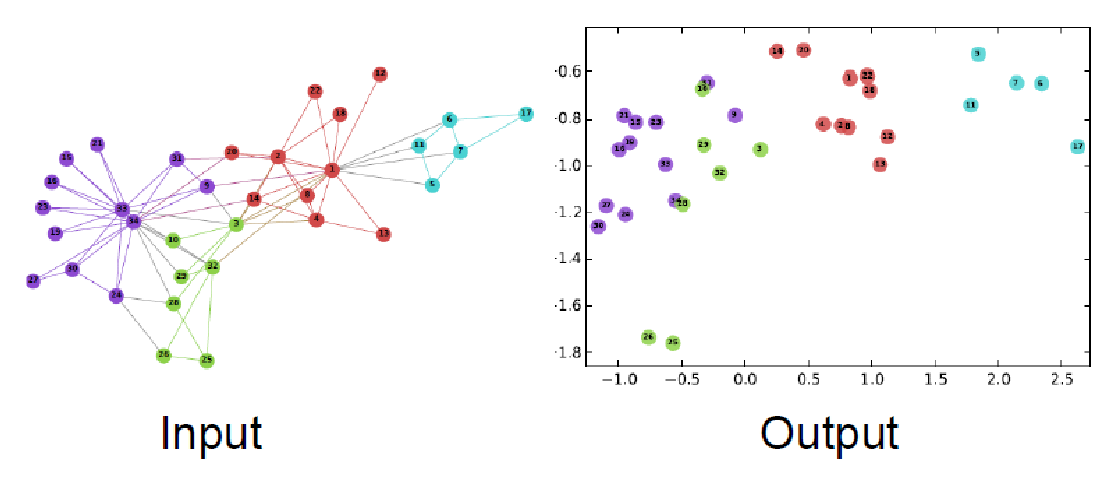 例: Zachary's Karate Club network嵌入效果
例: Zachary's Karate Club network嵌入效果
假设我们有一个图G,我们希望为G的节点V设计一个嵌入。目标是编码节点,使得嵌入空间中的相似性近似于图中的相似性。我们有3个设计选择:编码器、解码器和目标相似性函数。
-
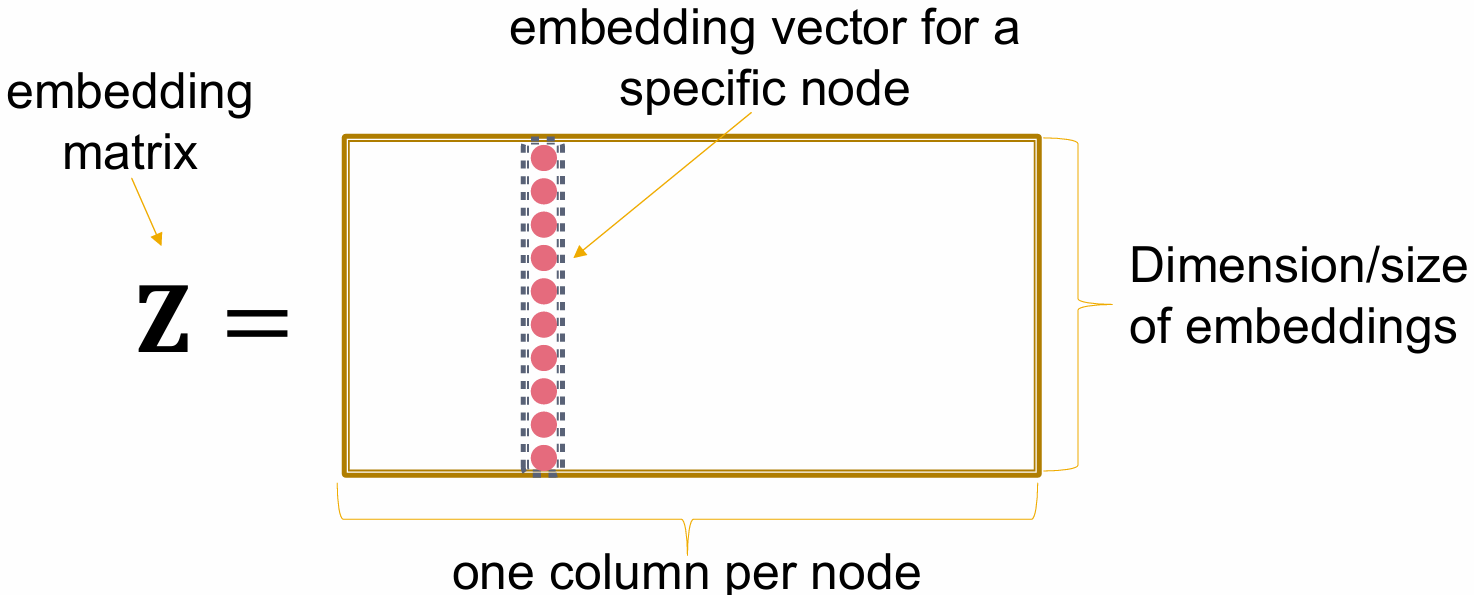
编码器:\(Enc: V → \mathbb R^{(d×|V|)},Enc(u) := z_u\)。
- 这可以被定义为从节点到向量的简单查找表(d(嵌入维数)行, |V|(图节点个数)列的矩阵)。在这种情况下,它是一个浅层编码器。
- 使用GNN的深层编码器将在第5.1节中介绍。
- 这是唯一的可学习函数。
- 解码器:给定两个嵌入,测量相似性。通常选择为点积 \(Dec(z, w) = z·w\)
- 相似性:节点之间的相似性度量。这可以是图中的距离、邻域拓扑等。它由编码器和解码器的组合近似。\(similarity(u, v) ≃ Dec(Enc(u), Enc(v))\)。
- 在本例中,\(similarity(u, v) ≃ z_u· z_v\)
- 这可以被定义为从节点到向量的简单查找表(d(嵌入维数)行, |V|(图节点个数)列的矩阵)。在这种情况下,它是一个浅层编码器。
许多方法都源于这种简单的设置,包括DeepWalk和node2vec。
2.1 随机游走嵌入 (Random Walk Embedding)¶
基于随机游走的无监督/自监督节点相似性度量在这种情况下,我们不使用节点标签或特征。嵌入是任务无关的,并且不使用任何节点标签或特征。选择随机游走的理由如下:
- 表达性:灵活的随机定义的节点相似性,结合了低阶和高阶邻域信息。
- 效率:在训练时不需要完全遍历图。
我们定义:
- 向量\(Enc(u) := z_u\):节点u的嵌入。
- 概率\(P(v|z_u)\):从u开始的随机游走中, 访问节点v的预测概率。
- Softmax函数:将k个值的向量转换为总和为1的k个概率: \(σ(z)_{i} =\frac {e^{ z_{i} }} { \sum_{i=1}^K e^{z_i}}\)
- 归一化的同时, 让大数更大,小数更小
- Sigmoid函数:将\(\mathbb R\)压缩到(0, 1): \(S(x) = \frac{1} {1 + e^{ -x }}\)
- 随机游走是一系列随机顶点\(v_0, v_1, ...\),使得\(v_{(i+1)}\)是从\(N(v_i)\)中随机选择的。
- 目标相似性函数为: \(similarity(u, v) := P(u, v出现在G上的随机游走中)\)
- 我们选择一个随机游走策略R,并使用这种策略来确定\(P_R(v|u)\),即从u开始的随机游走访问v的概率。策略定义了\(N_R(u)\),这是一个从u开始的所有短固定长度随机游走收集的随机多重集(可以有重复,因为节点可以多次访问,本质上是一个概率分布)。
现在我们可以用数学方式表述目标函数。负对数似然为:
\(L(Enc) := -\sum_{u∈V} log P(N_R(u)|z_u) = -\sum_{u∈V} \sum_{v∈N_R(u)} log P(v|z_u)\)
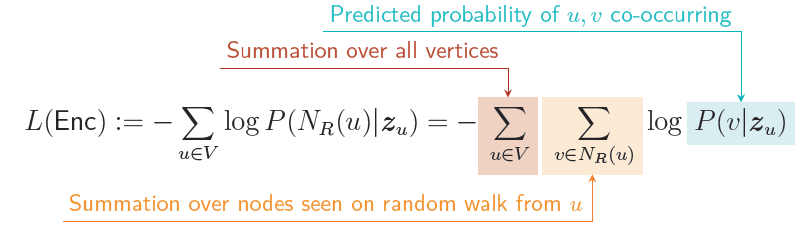
- 负对数似然negative log-likelihood: 机器学习中常见的损失函数,用于衡量模型的预测分布与真实分布之间的差距
我们使用softmax来参数化\(P(v|z_u)\)。本质上,我们将指数化的相似性分数\(\exp{(z_u·z_v)}, 即e^{z_u·z_v}\)视为未归一化的概率:\(P(v|z_u) := \frac{\exp{(z_u·z_v)}}{\sum_{n∈V} \exp{(z_u·z_v})}\) 然而,这个函数的计算成本很高。两个\(\sum_{n∈V}\)循环已经给出了\(O(|V|^2)\)的时间复杂度。解决这个问题的方法是负采样,它提供了估计: \(log\frac{\exp({ z_u·z_v})} {\sum_{n∈V} \exp({z_u·z_n})} ≃ log\ \sigma(z_u·z_v) - \sum_{i=1}^k {log\ \sigma(z_u·z_{n_i})} ,\ n_i ∼ P_v\)
其中\(P_v\)是V上的概率分布。而不是相对于所有节点进行归一化,只需相对于k个随机负样本\(n_i\)进行归一化。
- 我们可以选择\(P_V\),使得 \(P_V(n) ∝ degree(n)\)
- 负样本的数量k通常选择为5到20,因为:
- 较高的k值可以提供更稳健的估计
- 较高的k值对应于负事件的更高偏差
- 关于负采样: https://arxiv.org/pdf/1402.3722.pdf
有了这些,我们可以稳健地评估 \(∂L/∂z_u\) ,并执行随机梯度下降(SGD)以优化Enc。
随机梯度下降的回顾¶
在随机游走嵌入的设置中回顾随机梯度下降算法:
- 随机初始化所有u的\(z_u\)。
- 对所有u:
- 计算\(∂L/∂z_u\)
- 执行一步更新 \(z_u ← z_u - η·∂L/∂z_u\)。η是学习率。
- 返回步骤(2),直到收敛。
对于随机游走策略R,有几种不同的选择。在DeepWalk中,这只是从每个节点开始的无偏随机游走,但这可能过于受限。在node2vec中,策略被选择为将具有相似网络邻域的节点嵌入到特征空间中更接近的位置。我们将这视为一个最大似然优化问题,该问题独立于下游预测任务。关键观察是灵活的 \(N_R\) 定义可以产生丰富的节点嵌入。
两种经典的邻域定义策略是:广度优先搜索(BFS)和深度优先搜索(DFS)。我们可以通过两个参数在这两者之间进行插值:
- 返回参数p:返回到前一个节点的概率。
- 进出参数q:向外(DFS)与向内(BFS)移动的概率。直观上,q是插值参数。
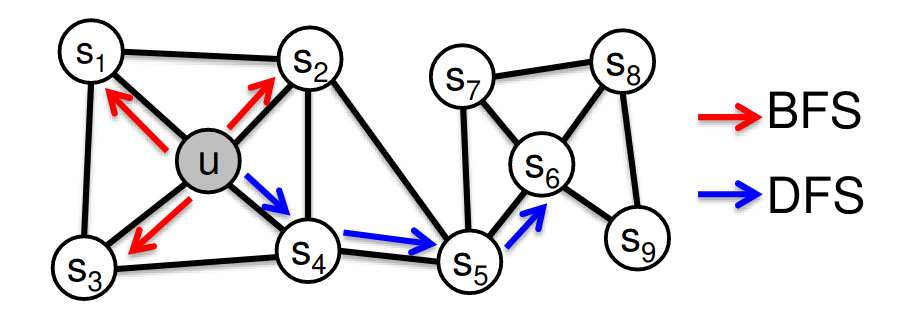 BFS和DFS策略生成的邻域\(N_R\)的比较。BFS提供邻居的微观视图,而DFS提供宏观视图
BFS和DFS策略生成的邻域\(N_R\)的比较。BFS提供邻居的微观视图,而DFS提供宏观视图
我们定义一个有偏的二阶随机游走来探索网络邻域。假设我们刚刚沿着边\((s_1, w)\)旅行,现在处于节点w。在N(w)中前方有三个选择。
- 返回到\(s_1\)(距离0),权重为1/p
- 保持在\(N(s_1)\)中(距离1),每个节点的权重为1
- 离开\(N(s_1)\)并进一步探索(距离2),每个更远的节点的权重为1/q

BFS类游走具有较低的p值(易于回溯),而DFS类游走具有较低的q值。在2017年的一项调查中,node2vec在节点分类任务中表现更好,而其他方法在链接预测任务中表现更好。没有一种方法能在所有情况下获胜。随机游走方法通常更高效。
2.2 嵌入整个图 (Embedding Entire Graphs)¶
有时我们希望将整个图嵌入到某个嵌入空间中。这可以用于例如对分子进行有毒/无毒分类或识别异常图。 一种简单的方法是对现有节点嵌入求和: \(z_G := \sum_{v∈G} z_v\)
另一种方法是引入一个“虚拟节点”来代表子图,并运行节点嵌入算法以使用其嵌入。我们将讨论层次嵌入,它通过逐步总结图来生成嵌入。
2.3 与矩阵分解的关系 (Relations to Matrix Factorization)¶
回想一下,编码器可以被视为一个嵌入查找表,大小为d×|V|。 最简单的节点相似性是邻接矩阵\(A_{u,v}\): 当两个节点u, v通过边连接时,它们被认为是相似的,否则不相似。即\(z_{v}^Tz_{u}=A_{u,v}\)
- 因此, node embedding可以是矩阵分解\(A = Z^TZ\)。
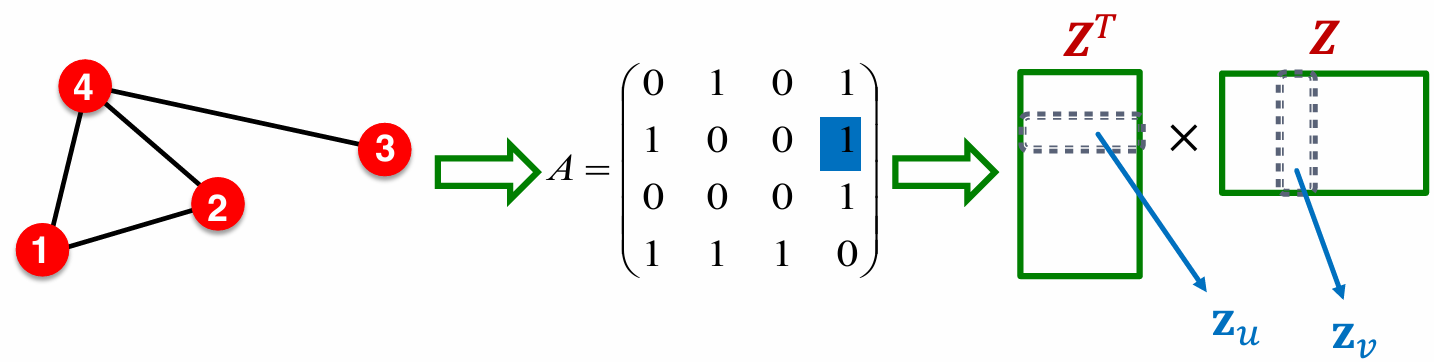
由于d ≪ |V|,这种分解无法精确完成,因为存在秩问题,因此我们可能需要优化以最小化Frobenius范数 \(min_Z ||A - Z^TZ||_F\)。在DeepWalk的例子中,嵌入分解矩阵为 \(log\left( vol(G) / \left( \frac{1}{T} \sum_{t=1}^T (D^{-1}A)^r D^{-1} \right) - \log b \right)\) 其中:
- 图的体积 \(vol(G) := \sum_{i,j} A_i,j\)
- 上下文窗口大小 \(T := |N_R(u)|\)
- 度矩阵 \(D_{u,u} := deg\ u\)
- r: 归一化邻接矩阵的幂
- b: 负样本数量
本质上,\(D^{-1}A\)是随机游走的马尔可夫矩阵。
2.4 应用与局限性 (Applications and Limitations)¶
嵌入可用于以下场景:
- 聚类/社区检测
- 节点分类
- 链接预测:基于(zi, zj)预测边(i, j)
- 图分类:对\(z_G\)进行分类
通过矩阵分解和随机游走进行节点嵌入存在一些局限性:
- 需要\(O(|V|·d)\)个参数。
- 节点之间无法共享参数,每个节点都有其独特的嵌入。
- 传导性:只有在看到图中的所有节点后,才能生成嵌入。无法为训练集中未出现的节点获得嵌入。
- 无法捕获局部拓扑的结构相似性。
- 无法利用节点、边和图的特征。
深度表示学习和图神经网络缓解了这些局限性,这将在第4节和第5节中详细介绍。
3 图神经网络¶
回顾第2讲,节点嵌入将节点映射到d维嵌入空间,使得图中相似的节点在嵌入空间中靠得更近。为了学习这样的嵌入,我们需要定义编码器(Enc)、解码器(Dec)和目标相似度函数(similarity(u, v))。今天我们讨论基于图神经网络(GNN)的一类深度学习方法。我们使用深度图编码器作为Enc。现代机器学习工具箱基于规则、重复的格子或网格,这些无法轻易适应图,因为图的结构比矩形网格复杂得多。图没有固定的节点顺序或参考点,并且图通常是动态的。
3.1 深度学习基础¶
这是对深度学习的简要介绍
插曲:监督学习¶
在监督学习中,我们给定输入x,目标是预测输出y。输入x可以是向量、序列、矩阵、图。我们将任务公式化为优化问题:
其中:
- \(\theta\)是一组我们要优化的参数。例如,在浅层编码器中,\(\theta = \{Z\}\)。
- L(\(\mathcal L\))是损失函数。
常见的L选择:
- \(L^2\)损失:\(L(\mathbf y, \mathbf {\hat{y}}) := \|\mathbf y - \mathbf {\hat{y}}\|^2\)
- 交叉熵Cross Entropy:\(L(\mathbf y, \mathbf{\hat{y}}) := -\sum_{i=1}^C y_i \log \hat{y}_i\),其中\(\mathbf y \in \{0, 1\}^C\)是一个类别的one-hot编码,而\(\mathbf {\hat{y}} \in [0, 1]^C\)是一个概率向量(\(\sum \hat{y} = 1\))
- 在后续内容中有更详细的介绍: 损失函数
优化问题通过梯度来解决:
- 梯度\(\nabla_{\theta}{L}=(\frac{\partial{L}}{\partial\theta_{1}},\frac{\partial{L}}{\partial\theta_{2}},..)\)是沿最大增加方向的方向导数。
其中, \(\theta\)是模型参数的集合, 是一个向量/矩阵, 包含模型中所有需要优化的参数
- 一个迭代算法更新\(\theta \leftarrow \theta - \eta \nabla_\theta L\),在\(\nabla_\theta L\)的反方向移动\(\theta\)直到收敛。
- \(\eta\)是学习率
- 对整个训练集评估梯度可能很昂贵,因此通常\(\nabla_\theta L = \sum_{i=1}^n \nabla_\theta L(y_i, f(x_i; \theta))\)通过一个随机样本\(\sum_{i \in I} \nabla_\theta L(y_i, f(x_i; \theta))\)来近似,其中\(I \subset \{1, \ldots, n\}\)。这就是随机梯度下降(stochastic gradient descent, SGD),I是批次batch。\(|I|\)是批次大小batch size,整个数据集的完整遍历次数称为epoch。
- batch: 在SGD训练中, 在训练集中取batchsize个样本进行训练
- iteration: 模型在一个batch上的一次训练过程
- epoch: 整个数据集被模型完全训练一次(不同batch抽到的样本不同, 即无放回抽样/独立同分布抽样)
- 其他高阶优化器包括RMSprop、Adam、Adagrad等。
多层感知机(multi-layer perceptron, MLP是通过堆叠形式为\(x^{(l+1)}= \sigma(\mathbf Wx^{(l)} + b)\)的层构建的神经网络,其中W、b是可学习的,\(\sigma\)是称为激活函数的非线性函数。
3.2 图的深度学习¶
假设我们有一个图G,其顶点集为V,邻接矩阵为\(A \in \{0, 1\}^{|V| \times |V|}\),节点特征为\(X \in \mathbb{R}^{|V| \times m}\)
一个朴素的方法是将有结构的邻接矩阵A和特征结合起来, 输入到一个深度神经网络中。这个想法的问题在于:
- \(O(|V|+d)\)参数
- 图的大小固有地嵌入到神经网络的大小中
- 如果图上新增节点, 会导致神经网络输入向量维度变化(\(|V|+d->|V|+1+d\))
- 对节点顺序敏感, 即不具有置换不变性
- 节点顺序影响邻接矩阵结构
一个解决方案是使用卷积网络,它使用一个滑动核,在图的所有点上都是不变的。但是图上没有固定的局部性或滑动窗口的概念,并且图没有给出其顶点的固有顺序。 考虑我们学习一个函数f,将图\(G := (A, X)\)映射到\(\mathbb{R}^d\)中的一个向量。并且我们希望对于图的两个不同顺序\(f(A_1, X_1) = f(A_2, X_2)\)。对于任何图函数\(f : \mathbb{R}^{|V| \times m} \times \mathbb{R}^{|V| \times |V|} \rightarrow \mathbb{R}^d\),
- 如果对于任何置换矩阵P,\(f(A, X) = f(PAP^T, PX)\),则f是置换不变permutation Invariance的。
- 如果对于任何置换矩阵P,\(Pf(A, X) = f(PAP^T, PX)\),则f是置换等变permutation equivariant的。
例如:
- \(f(A, X) = 1^TX\)是置换不变的(所有节点特征的求和)。
- \(f(A, X) = X\)是置换等变的。
- \(f(A, X) = AX\)是置换等变的。
图神经网络由多个置换等变/不变层组成。其他神经网络架构(例如MLP)不具备此属性。
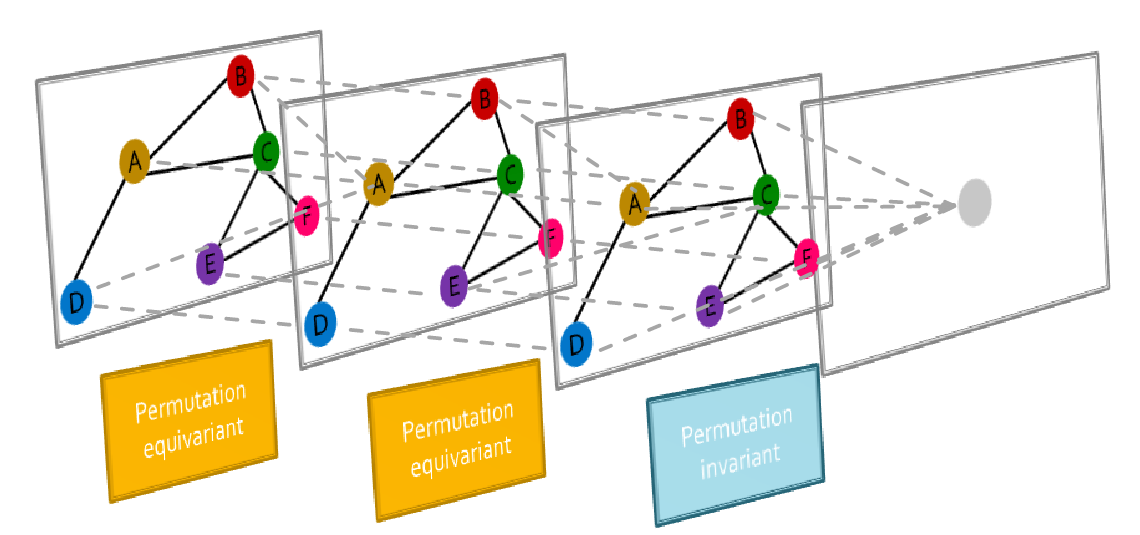 由置换等变卷积层和置换不变池化层组成的GNN的一般结构
由置换等变卷积层和置换不变池化层组成的GNN的一般结构
3.3 图卷积网络¶
计算图&聚合¶
一个关键的观察是,节点的邻域定义了一个计算图。信息可以沿着这个计算图传递,以结合来自图的不同部分的信息。以这种方式构建的模型可以具有任意深度。
- 这里的"深度"指的是计算图的层数, 而非神经网络的层数
- 根据"六度空间"理论, 构建的模型并不需要太深
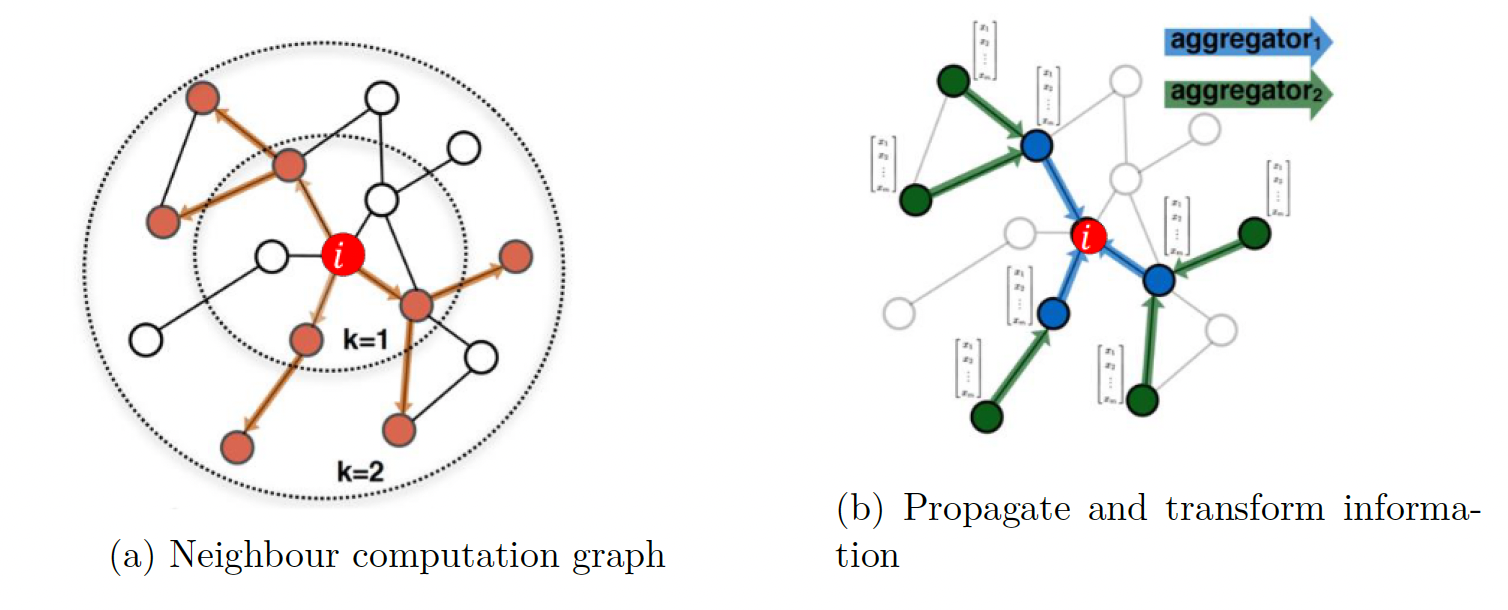 由节点的邻域结构定义的计算图。每个节点根据它的邻域定义一个计算图,这可以在节点之间改变。
由节点的邻域结构定义的计算图。每个节点根据它的邻域定义一个计算图,这可以在节点之间改变。
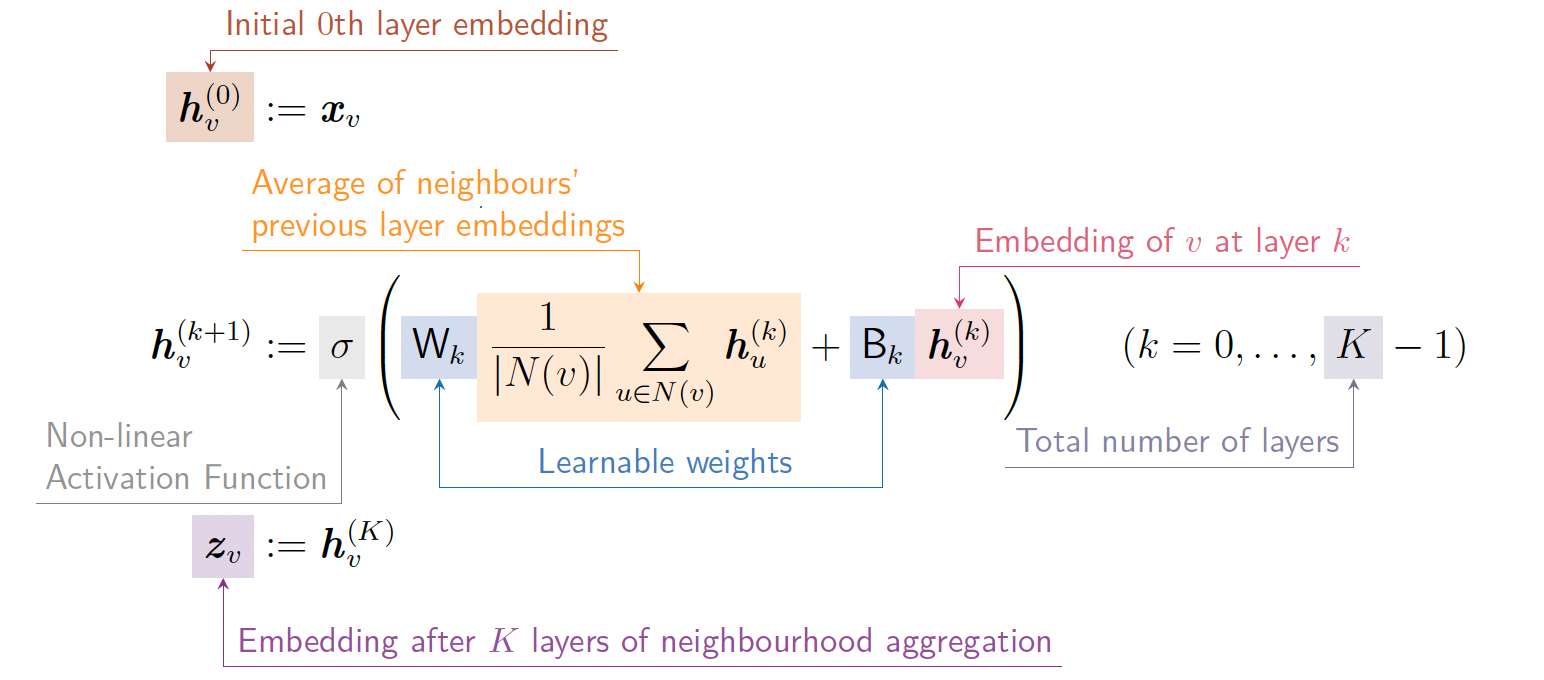
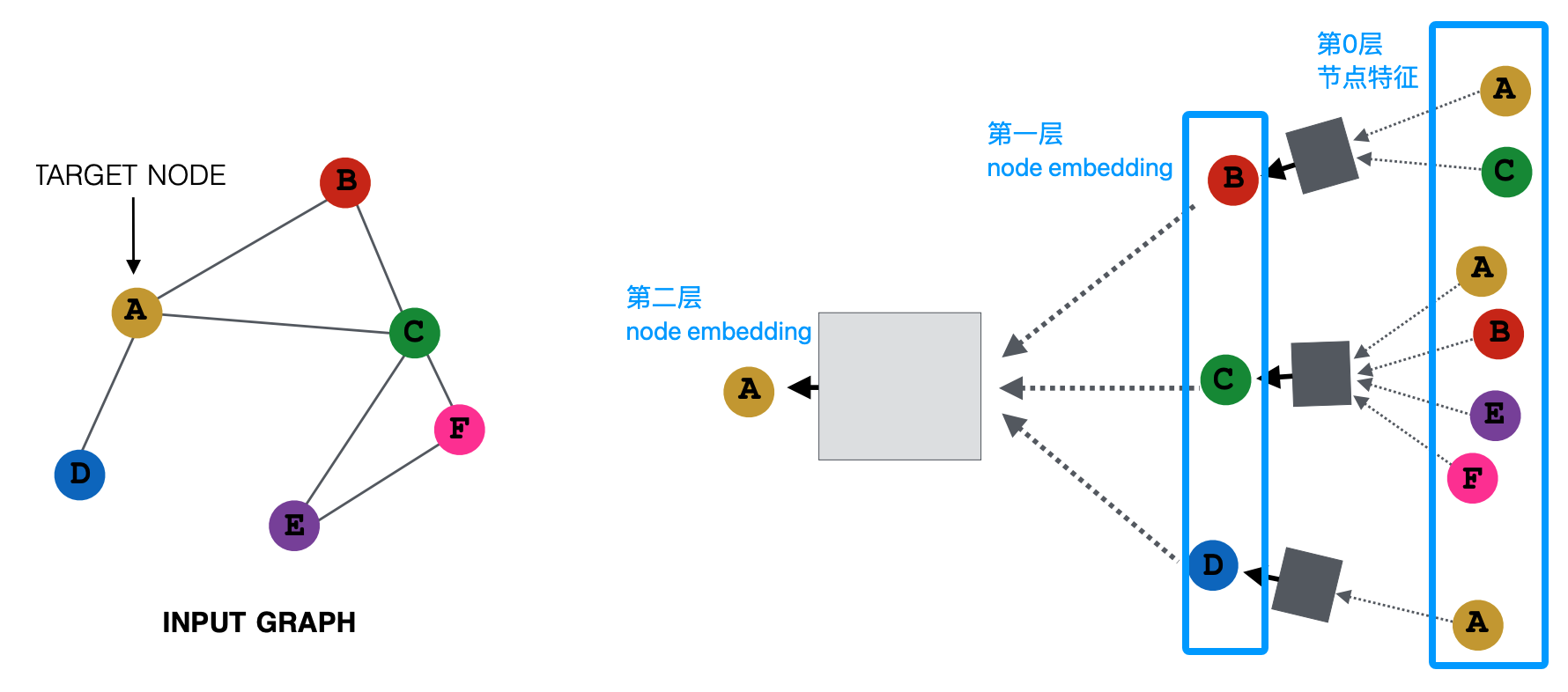 节点v的第0层嵌入是其输入特征\(x_v\),第k层嵌入是从第k-1层嵌入构建的。邻域聚合aggregation是跨层聚合信息的方法。一个基本方法是平均邻居的信息并应用一个神经网络。这个思路形成了深度编码器:
节点v的第0层嵌入是其输入特征\(x_v\),第k层嵌入是从第k-1层嵌入构建的。邻域聚合aggregation是跨层聚合信息的方法。一个基本方法是平均邻居的信息并应用一个神经网络。这个思路形成了深度编码器:
- \(h_{v}^{(0)}\): 初始第0层嵌入 (注: m维向量)
- \(\sigma\): 非线性激活函数
- \(\frac{1}{|N(v)|} \sum_{u \in N(v)} h_u^{(k)}\): 上一层嵌入的邻居平均值
- \(W_{k}, B_{k}\): 可学习权重
- \(W_{k}: d\times d'\)第k层的权重矩阵, 将d维输入变换到d'维特征 (所以有两种权重矩阵, \(d\times m和d\times d\))
- \(B_{k}: 1\times d\): 第k层的偏置项(向量)
- \(h_{v}^{(k)}\): 第k层的节点v的嵌入 (注: d维向量)
- K: 总层数
- \(z_{v}\): 聚合邻域K层后获得的节点嵌入 (注: d维向量)
GNN计算是置换等变的。可以通过更新聚合和变换的权重矩阵\(W_k, B_k\),使用SGD训练GNN。许多聚合可以有效地作为稀疏矩阵操作执行。如果定义\(H^{(k)} := [h_1^{(k)}, \ldots, h_{|V|}^{(k)}]^T\),则可以用矩阵简化:
- 对角矩阵\(D_{v,v} := \deg(v)\)
我们可以将更新函数重新写成矩阵形式:
- \(\mathbf D^{-1}\mathbf A\mathbf H^{(k)}W_k^T\): 邻域聚合
- \(\mathbf H^{(k)}B_k^T\): 自变换
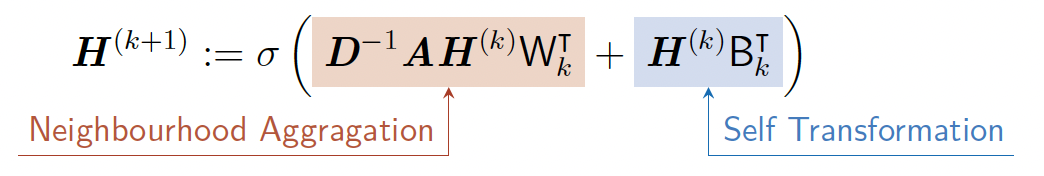
不是所有的gnn都可以用矩阵形式表示,特别是当聚合函数较为复杂时。
训练GNN¶
有监督设置:我们可以最小化节点标签\(y_v\)与节点嵌入\(f(z_v)\)的损失函数,即\(\min_\theta L(y_v, f(z_v))\)
例如,预测节点上的二进制标签的训练可以包含二进制交叉熵或逻辑损失函数的形式

无监督设置:当没有节点标签时,我们可以使用图的结构作为监督。要求相似的节点具有相似的嵌入。即我们优化
其中\(y_{u,v}\)是节点的相似度分数。
总结:
- 定义邻域聚合函数
- 定义嵌入上的损失函数
- 在一组节点上进行训练,即一批计算图。
- 生成节点嵌入(即使对于模型从未训练过的节点)。
GNN是归纳的,而不是自适应的。相同的模型可以泛化到未见的节点。
3.4 GNNs包含CNNs¶
图像的CNN和图的GNN对比
GNN可以被视为比CNNs更一般的架构类别。在具有3×3滤波器的卷积层中,可以公式化为
- \(N(v)\)是像素v的8个邻居
关键区别是我们可以为图像中的像素v的每个“邻居”u学习不同的\(W_{l,u}\)。为此,我们可以选择相对于中心像素v的特定顺序。CNN可以被视为具有固定邻居大小和顺序的特殊GNN。CNN不是置换不变的或等变的。
4 图神经网络的一般视角¶
公开的2021版课程视频与2024版笔记有些不同, 2024省略了pagerank, 半监督学习等内容, 在这里放个链接: Stanford CS224W: Machine Learning with Graphs | 2021 | Lecture 7.1 - A general Perspective on GNNs
在本节中,我们扩展了之前构建的图神经网络(GNNs),并创建了一个通用的GNN框架。一个GNN由以下5部分组成:
- 消息
- 聚合函数
- 一个GNN层由消息和聚合组成的
- 不同的实现包括图卷积网络(GCN)、GraphSAGE和GAT(Graph Attention图注意力)
- 层连接: 层连接指的是层之间的拓扑连接(如何堆叠layer),包括跳跃连接。
- 图增强:特征增强,结构增强等
- 核心思想是,对于许多我们稍后会解释的问题,不应直接将原始输入图用作计算图
- 学习目标:有监督/无监督,节点/边/图级目标
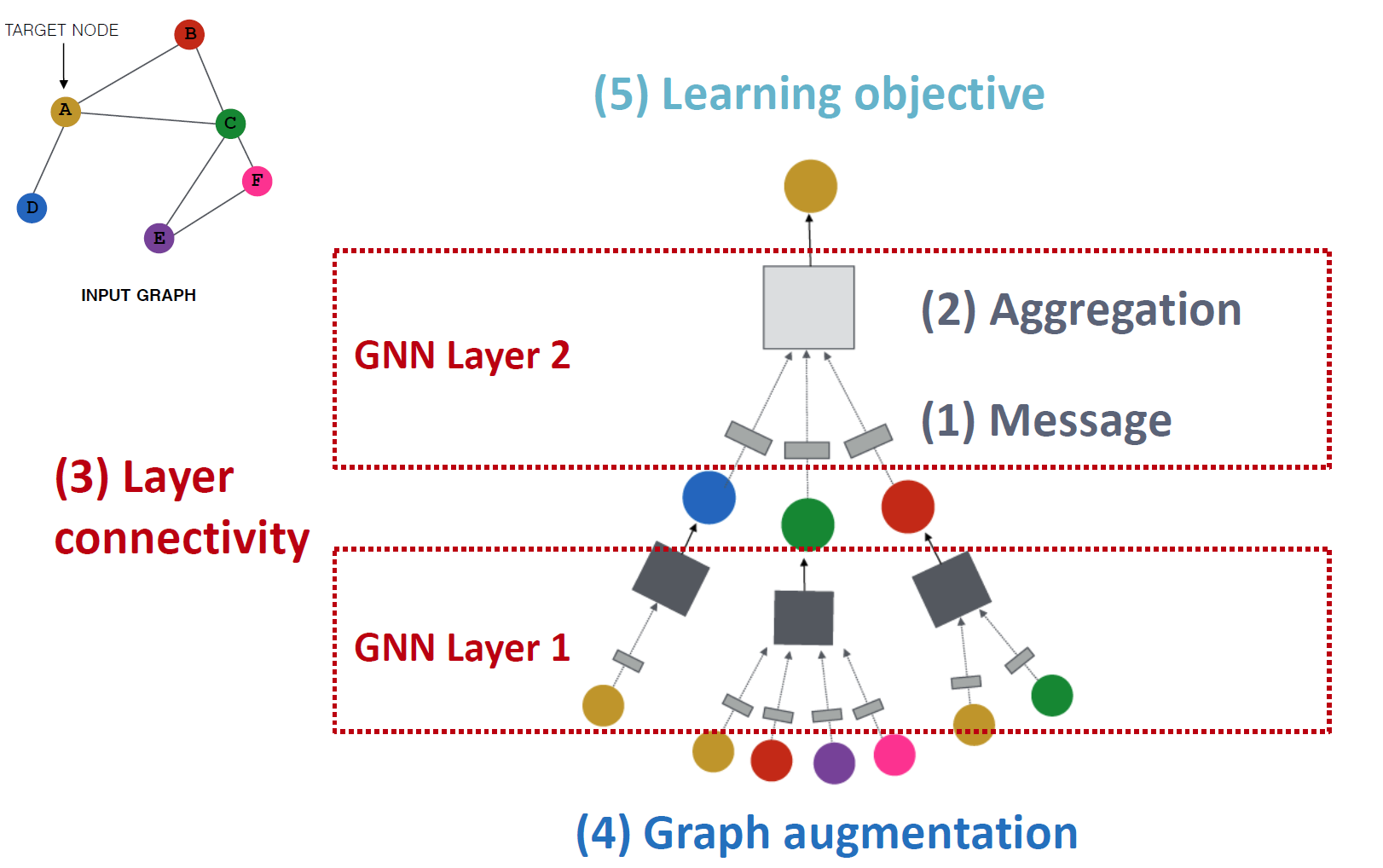
4.1 A Single Layer of GNN¶
单层GNN的作用是将(可变大小的)一组输入向量压缩成一个向量。这涉及到取输入\(h^{(l-1)}_v和h^{(l-1)}_{u \in N(v)}\),并输出节点嵌入\(h^{(l)}_v\),主要分为消息Message和聚合Aggregation两步
(1) 消息函数message function将每个节点的隐藏状态转换为消息,该消息将稍后发送给其他节点。
- 对于线性层的消息函数: \(m^{(l)}_u := W^{(l)}h^{(l-1)}_u\)
Question: 一个节点可以发送不同的消息给不同的邻居吗? Yes, 在GAT网络中可以看到例子
(2) 聚合函数aggregation function定义了如何组合邻居的消息。
- 一个例子是\(h^{(l)}_v\)可以是求和,平均或最大值
Question:在聚合中,节点v自己的信息可能会丢失,因为\(h^{(l)}_v\)不直接依赖于\(h^{(l-1)}_v\)。 解决方案是将自身的\(h^{(l-1)}_v\)包含在\(h^{(l)}_v\)的计算中。我们可以为v自己计算一个消息,然后使用
- concat为拼接函数 (3) 非线性激活函数跟随消息或聚合, 以增加表达性。
- 如果只有线性层叠加, 最后的结果即为多个矩阵左乘, 计算后转换一个矩阵的线性变换, 表达能力不够好
Examples¶
前面我们介绍了消息-聚合的通用GNN架构, 看一些例子来深入理解
图卷积网络(GCN)¶
图卷积网络(GCN),其中消息和聚合函数定义为:
- 激活函数:\(\sigma\)
- 消息函数:\(m_u^{(l)} = \frac{1}{\text{deg}(v)} W^{(l)} h_u^{(l-1)}\)
- 归一化:通过节点v的度进行归一化
- 聚合函数:\(h_v^{(l)} = \sigma \left( \sum_{u \in N(v)} m_u^{(l)} \right)\)
- GCN假设图中包含自环,并且这些自环被包含在求和中
GraphSAGE¶
基于GCN进行了拓展
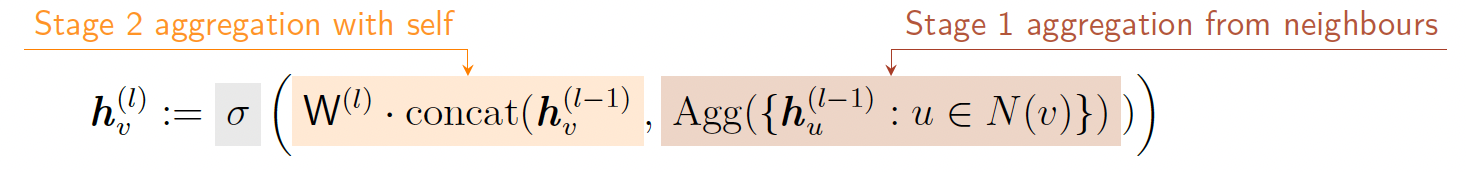
消息:在聚合函数Agg(·)中计算。
有几种不同的聚合函数Agg(·):
- 均值:邻居的加权平均值(和GCN一样)
- 池化:转换邻居向量并应用对称向量函数(均值或最大值)
- LSTM:将LSTM应用于重新排列的邻居
可选地,在每一层对\(h_v^{(l)}\)应用\(L^2\)(2范数)归一化。如果没有\(L^2\)归一化,嵌入向量的尺度会不同。在某些情况下,归一化可以提高性能。
图注意力网络(GAT)¶
注意力权重\(\alpha_{v,u}\):GAT为节点v来自其他节点u的消息分配不同的权重。
- 当\(\alpha_{v,u} = \frac{1}{|N(v)|}\)时,注意力机制退化为GCN/GraphSAGE(对于不同的节点u, 权重都相同)
- \(\alpha_{v,u}\)是基于图的结构属性(特别是节点度)显式定义的
- GAT的注意力机制受到认知注意力的启发,专注于输入数据的重要部分
注意力系数attention coefficients:权重\(\alpha_{v,u}\)实际上由注意力系数定义
然后使用softmax将\(e_{v,u}\)归一化为注意力权重:
- 注意力机制 attention mechanism即为计算注意力权重\(\alpha_{v,u}\), 关键是注意力系数定义中的\(a(\cdot)\)
- 注意力机制a可以使用一个线性层来实现
在多头注意力(Multi-head Attention)中,使用多个注意力分数并将每个注意力“头”的结果进行聚合:
- 注意力机制训练过程中, 会得到多个局部最优的\(\alpha_{v,u}[j]\), 将他们聚合起来, 能得到更丰富的特征表示 注意力机制的优点:
- 隐式指定邻居的不同重要性
- 计算效率高:注意力可以在图的所有边上并行计算
- 存储效率高:稀疏矩阵操作不需要超过\(O(V + E)\)的条目,参数数量固定
- 局部化:仅关注局部邻域
- 归纳能力:不依赖于全局图结构
4.2 实践中的GNN层¶
在实践中,经典的GNN层是一个起点 我们可以通过考虑通用的GNN层设计来获得更好的性能
- 即现代深度学习模块, 例如批量归一化batch normalization,dropout,注意力/门控等。
- 在gnn中,dropout应用于消息函数的线性层。
- 一个特别的注意点是激活函数:经验上,参数化ReLU (Parametric ReLU)函数,定义为\(\text{PReLU}(x) := \max(x, 0) + a \min(x, 0), a是一个可训练参数\)比ReLU表现更好。 设计新的GNN层仍然是一个活跃的研究前沿。你可以在GraphGym中探索多样化的GNN设计或尝试自己的想法。
4.3 堆叠GNN层 *¶
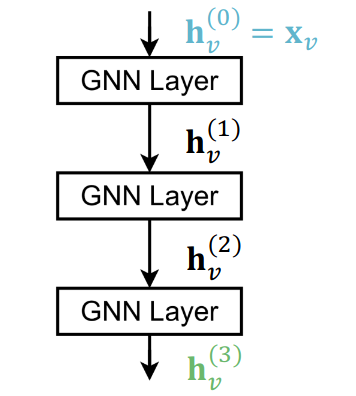
如何将GNN层连接成GNN?标准方法是顺序堆叠GNN层。
这导致了过平滑问题(over-smoothing problem)。由于每个节点的接收域变得越来越大,两个不同节点的接收域最终会收敛到一个,这导致所有节点嵌入变得收敛。因此:
1. 当堆叠GNN层时要小心。更多的层并不总是有帮助,与深度学习在其他领域不同。层的数量应该比接收的半径多一点,但不应该太多。
- 解决方案1:增加每个GNN层的表达能力:我们可以使聚合/转换transformation成为一个深度神经网络。
- 解决方案2:添加不传递消息的层。GNN不一定只包含GNN层。我们可以在GNN层之前和之后添加MLP层,作为预处理和后处理层。在实践中,添加这些层是有益的。
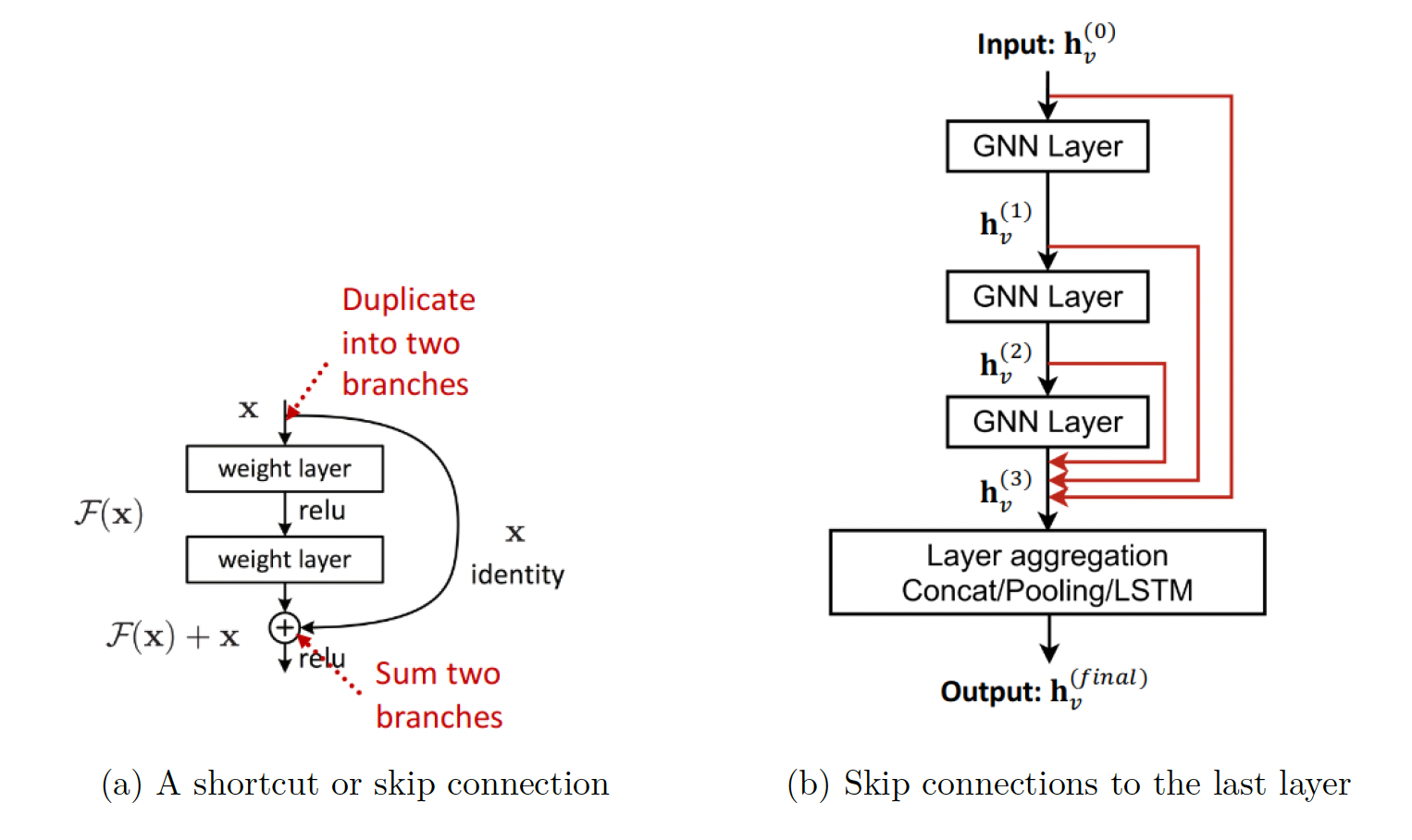
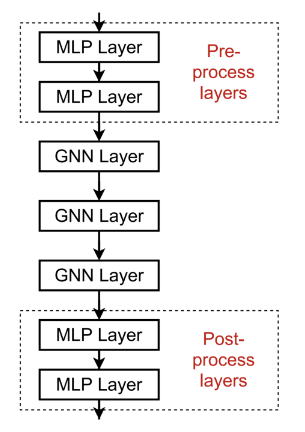 2. 在GNN中添加跳跃连接:由于早期的GNN层有时可以更好地区分节点,我们添加了跳跃连接。跳跃连接创建了模型的混合。我们得到了一个浅层和深层GNN的混合。
- 当我们有N个跳跃连接时,信息有\(2^N\)种可能的传输路径。
- 跳跃连接的一个例子是:
2. 在GNN中添加跳跃连接:由于早期的GNN层有时可以更好地区分节点,我们添加了跳跃连接。跳跃连接创建了模型的混合。我们得到了一个浅层和深层GNN的混合。
- 当我们有N个跳跃连接时,信息有\(2^N\)种可能的传输路径。
- 跳跃连接的一个例子是: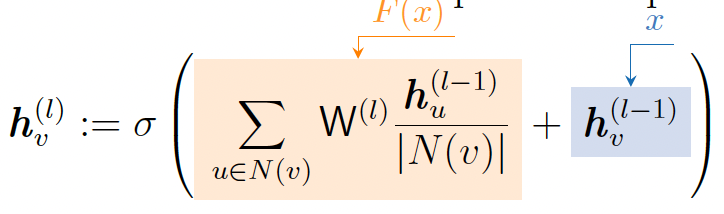 - 另一个选项是直接跳到最后一层
-
- 另一个选项是直接跳到最后一层
- 
4.4 GNN中的图操作¶
原始输入图并不总是适合作为计算图。原因可能是图的节点特征or图的结构
特征级¶
输入图缺乏特征(比如输入邻接矩阵):需要特征增强 - 为节点分配(相同的)常数特征值:但是表达能力不足。 - 为节点分配唯一ID:违背了归纳学习的原则(模型依赖于节点ID); 计算成本过高(用one-hot编码节点需要O(|V|))。 某些结构对GNN来说很难学习 - 例如,循环计数特征(v所在的循环长度)。我们可以将循环计数作为特征嵌入。 - 其他常用的增强特征是聚类系数,PageRank,中心性。
结构级 *¶
图太稀疏,导致消息传递效率低下 - 我们可以添加虚拟边:例如,通过虚拟边连接2跳邻居。直观上,我们使用\(A + A^2\)作为邻接矩阵,而不是仅仅使用A。这在二分图中很有用。 - 添加一个虚拟节点,连接到图中的所有节点。这在稀疏图中极大地改善了消息传递 图太密集,导致消息传递成本高昂 - 我们可以在消息传递期间对邻居进行采样。即在聚合期间,只有随机选择的\(N(v)\)的子集将他们的消息传递给v。 图太大(邻居过多),无法将计算图放入GPU。我们可以对子图进行采样以计算嵌入。 - 这将在以后的讲座中讨论:扩大GNN的规模。 在输入图恰好是最佳计算图的情况下,输入图不太可能被使用。
5 GNN增强与训练¶
到目前为止,我们已经介绍了图神经网络和节点嵌入。
5.1 使用GNN进行预测¶
通过创建的节点嵌入,我们可以执行不同的预测任务。不同层次的任务需要不同的预测头。
节点级预测¶
我们可以直接使用节点嵌入进行预测,使用线性预测头:
边级预测¶
使用节点嵌入对进行预测:
可以通过以下方式实现:
- 连接+线性层:
- 点积:
- 其中\(W\)可以是单位矩阵\(I\)(得到一个标量, 用于1维预测),或者是一组用于\(k\)维标签预测的矩阵。

图级预测¶
图级预测:
这类似于GNN中的聚合步骤。 对于较小的图,全局池化(如均值池化、最大池化、求和池化)效果很好。
- 全局均值池化: \(\hat{y}_G := \textcolor{red}{Mean}({h_v^{(L)} : v \in V(G)})\)
- 全局最大池化: \(\hat{y}_G := \textcolor{red}{Max}({h_v^{(L)} : v \in V(G)})\)
- 全局求和池化: \(\hat{y}_G := \textcolor{red}{Sum}({h_v^{(L)} : v \in V(G)})\) 主要问题是全局池化在大图上会丢失信息。

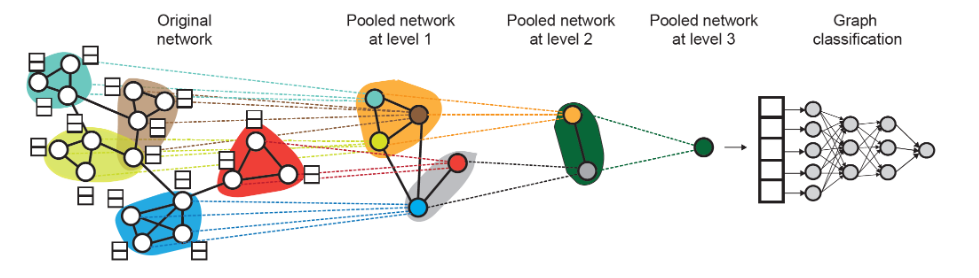
解决方案是分层聚合图。我们在每个池化层训练两个独立的GNN: - GNN-A:计算节点嵌入(嵌入任务) - GNN-B:计算节点所属的簇(聚类任务) 对于每个池化层,使用GNN-B的聚类分配来聚合GNN-A生成的节点嵌入。 - 同一层的GNN A和B可以并行执行(因为执行的是不同的任务, 互不依赖) 问题:GNN-A是否在整图上训练? - 在第一层聚类中,是的。在后续层中,它是在聚类后的图上训练的。
5.2 训练图神经网络¶
GNN训练的真值来自以下两种来源: - (监督学习)外部数据supervised labels:例如预测分子图的药物相似性。 - 节点标签\(y_{v}\): 如在citation network中, 一个节点代表一篇论文, label就标识论文所属的subject - 边标签\(y_{u,v}\): 在一个交易网络中, 每个边代表一笔交易, label就是这个交易是否存在欺诈行为 - 图标签\(y_{G}\): 在分子图Molecular Graph中, 图标签常用于标识一个分子是否具有某种特性/活性 - (无监督学习)图特征unsupervised signals:例如链接预测,预测两个节点是否相连。这有时被称为自监督学习。 - 节点级任务:预测节点的统计信息(如聚类系数、PageRank等) - 边级任务:进行链接预测,通过隐藏边来判断两个节点是否应连接 - 图级任务:预测图的统计信息(如判断两个图是否同构)。 有时这两者之间的界限并不明确。
5.3 损失函数¶
分类与回归¶
分类问题Classification: 标签\(y^{(i)}\)是离散的 - 如节点分类问题, label标识节点属于哪个分类(通常用one-hot表示) 回归问题Regression: 标签\(y^{(i)}\)是连续值 - 如预测分子图的药物相似性 GNN可以再这两种问题上应用, 区别在于loss function & evaluation metrics
Classification Loss¶
交叉熵Cross Entropy(CE)是较为常用的分类损失函数
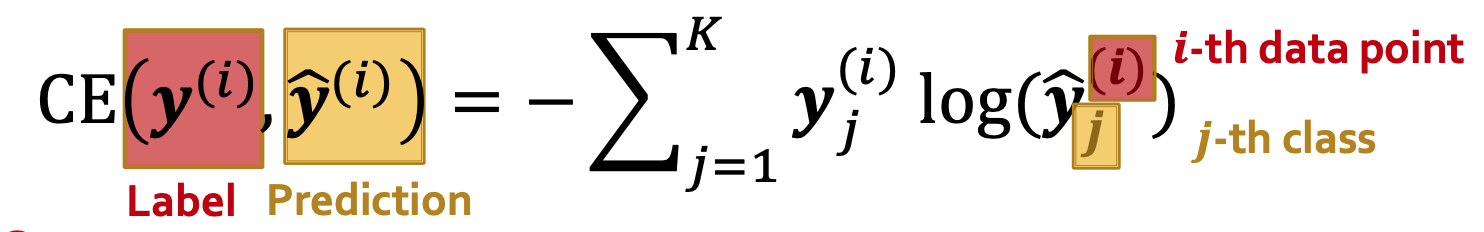 其中
- 标签\(\mathbf y^{(i)} \in \mathbb R^K\)是一个类别的one-hot编码,表示真实标签
- one-hot编码: 长度为类别数, 其中只有一个元素是 1,其它元素都是 0.如\(y^{(i)}=[0,0,1,0,0]\)表示在五类预测中, 第i个数据属于第3个分类
- \(\mathbf {\hat y}^{(i)} \in \mathbb R^K\)是一个概率向量(\(\sum \hat{y} = 1\)), 通常为c 用Softmax(⋅)归一化后的预测分类
经过N个训练样本得到的总损失即为
其中
- 标签\(\mathbf y^{(i)} \in \mathbb R^K\)是一个类别的one-hot编码,表示真实标签
- one-hot编码: 长度为类别数, 其中只有一个元素是 1,其它元素都是 0.如\(y^{(i)}=[0,0,1,0,0]\)表示在五类预测中, 第i个数据属于第3个分类
- \(\mathbf {\hat y}^{(i)} \in \mathbb R^K\)是一个概率向量(\(\sum \hat{y} = 1\)), 通常为c 用Softmax(⋅)归一化后的预测分类
经过N个训练样本得到的总损失即为
交叉熵损失的核心是对每个分类的类别 i,计算真实类别概率与预测概率之间的差异。具体来说:
- \(\log \hat{y}_i\) 是预测概率 \(\hat{y}_i\) 的对数。由于 \(\hat{y}_i\) 是一个概率值(0 到 1 之间),其对数值总是负数或者零(当 \(\hat{y}_i = 1\) 时 \(\log \hat{y}_i = 0\))。
- 注: 这里的概率在分类问题中常用前面提到的softmax来进行归一化输出
- \(y_i\) 是真实标签在第 i 类上的值,如果真实类别是第 i 类,则 \(y_i = 1\),否则 \(y_i = 0\)。这意味着对于其他类别,损失不会对其进行惩罚(因为 \(y_i = 0\))。
- 损失是所有类别损失的加权和,其中加权系数是 \(y_i\)。由于 \(y_i\) 只有一个为 1,其他为 0,因此交叉熵实际上只考虑真实类别的预测概率(不用管那堆sum)。
- 为了便于计算, 我们的优化目标: \(最大化预测概率\hat y_{i}\Rightarrow 最大化\log \hat{y_i}\Rightarrow 最小化(-\log\hat{y_i})\)
Softmax 函数常用于多类分类问题的神经网络最后一层,它将一个 N 维的向量转换为一个概率分布。 数学表达式: 给定向量 \(\mathbf{z} = [z_1, z_2, \dots, z_n]\) ,Softmax 输出为:\(p_i = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}\) 特点: 输出值在 (0, 1) 之间,且所有输出值的和为 1。 输出值可以解释为类别的概率。
Regression Loss¶
对于回归问题, 我们常用的计算方式是均方误差Mean Squared Error(MSE), 也称L2 Loss
对于输入数据/样本(i)的K类回归:
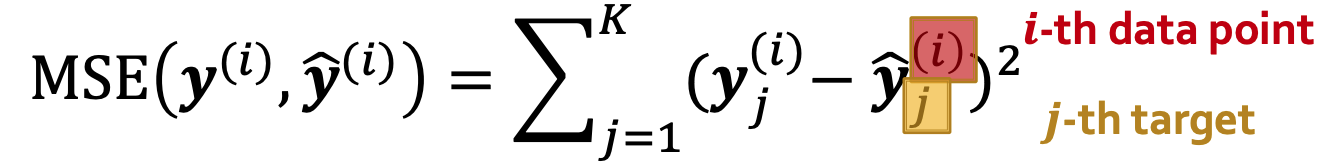 其中
其中
- 标签\(\mathbf y^{(i)} \in \mathbb R^K\)是样本i的实际值(向量)
- \(\mathbf {\hat y}^{(i)} \in \mathbb R^K\)是样本i的预测值(向量) N个训练样本得到的总loss即为:
5.4 评估指标 (Evaluation Metrics)¶
回归的评估指标¶
均方根误差 (Root Mean Square Error, RMSE)
- RMSE 是预测值与真实值之间差异的平方和的均值的平方根。它衡量了预测值与真实值之间的平均误差大小,对较大的误差更为敏感。 平均绝对误差 (Mean Absolute Error, MAE)
- MAE 是预测值与真实值之间绝对误差的平均值。它直接衡量了预测值与真实值之间的平均差异,不受异常值的影响。
多分类的评估指标¶
准确率 (Accuracy)\(\text{Accuracy} = \frac{1}{N} \sum_{i=1}^{N} 1[\arg\max(\hat{y}_i) = y_i]\)
- 准确率是分类正确的样本数占总样本数的比例。它适用于多分类任务,但当类别分布不均衡时可能不够敏感。
二分类的评估指标¶
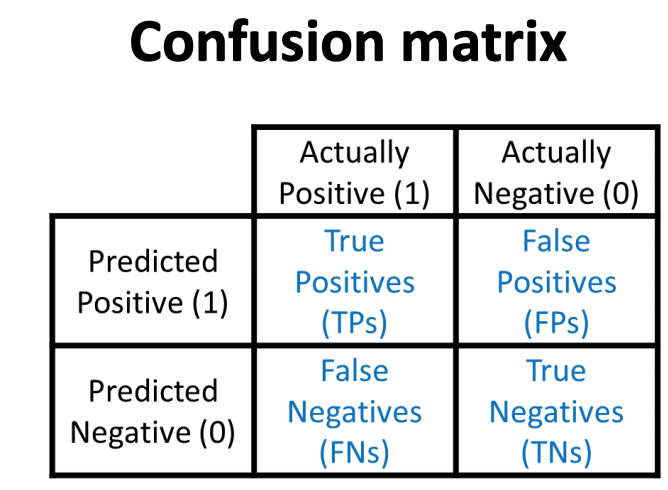 准确率 (Accuracy)
准确率 (Accuracy)
- 准确率是分类正确的样本数(包括真正例和真负例)占总样本数的比例。 精确率 (Precision, P)
- 精确率衡量了被预测为正类的样本中实际为正类的比例,反映了模型预测正类的可靠性。 召回率 (Recall, R)
- 召回率衡量了所有实际正类中被正确预测为正类的比例,反映了模型对正类的覆盖能力。 F1 分数 (F1-Score)
- F1 分数是精确率和召回率的调和平均值,综合考虑了精确率和召回率的平衡。 与分类阈值无关的指标 ROC 曲线(Receiver Operating Characteristic Curve)用于描述二分类器在不同分类阈值下的性能表现。它通过绘制真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)之间的关系来展示分类器的性能。
- TPR表示所有实际正例中被正确预测为正例的比例
- FPR表示所有实际负例中被错误预测为正例的比例
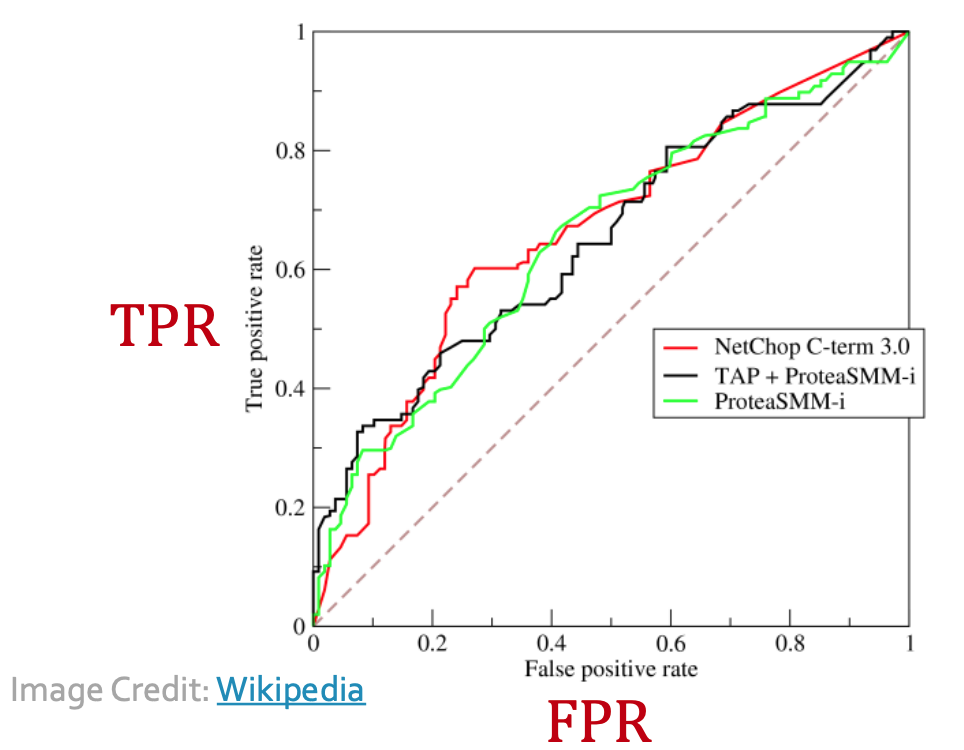
- ROC 曲线展示了在不同分类阈值下,分类器的真正例率和假正例率之间的权衡关系。曲线越靠近左上角,分类器性能越好。
- 虚线表示了一个随机分类器的ROC曲线 ROC AUC : 通过计算 ROC 曲线下的面积得到。
- ROC AUC 表示分类器将随机选择的正样本排在随机选择的负样本之前的概率。它衡量了分类器的整体性能,不受分类阈值的影响。
5.5 设置GNN预测¶
如何将数据集划分为训练集、验证集和测试集? 这三个数据集的用途如下:
- 训练集:用于优化GNN参数。
- 验证集:用于开发模型和超参数。
- 测试集:用于报告最终性能。 有时我们无法保证测试集真正被保留。在这种情况下,我们可以使用随机划分,并报告不同随机种子下的平均性能。
监督学习的数据集划分¶
与图像数据集相比,划分图数据集有其独特之处。在顶点和边的task中, 如果我们将图划分为不同的顶点,节点之间并不是独立的。因为消息传递机制的存在, 未标记的验证集或测试集中的节点会影响训练集中的节点预测。
- 比如训练集中的1, 2在训练时会依赖于neighbor3,4,5, 这造成了一定的信息泄露
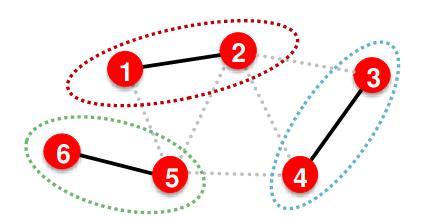 有两种解决方案:
有两种解决方案: - 直推设置 Transductive Setting:输入图在所有数据集中都可以观察到,但只有训练集有可见的标签。(只分割label)
- 归纳设置 Inductive Setting:打破划分之间的边以获得多个图。在这种情况下,不同组件中的节点才是真正独立的。(分割edge)
- 只有inductive适用于图分类。
自监督的数据集划分(链接预测)¶
在链接预测任务中,任务设置很棘手。这是一个自监督任务,我们需要自己生成标签和数据集。 一种实用的方法是隐藏GNN的边,并让GNN预测这些边是否存在。我们两次划分边:
- 在原始图中分配两种类型的边:消息边和监督边。消息边对GNN可见,而监督边则不可见。
- 将边划分为训练集/验证集/测试集。我们可以使用Inductive或Transductive设置。
- 例: 一个包含3张图的inductive dataset, 每个图都有自己的消息边和监督边
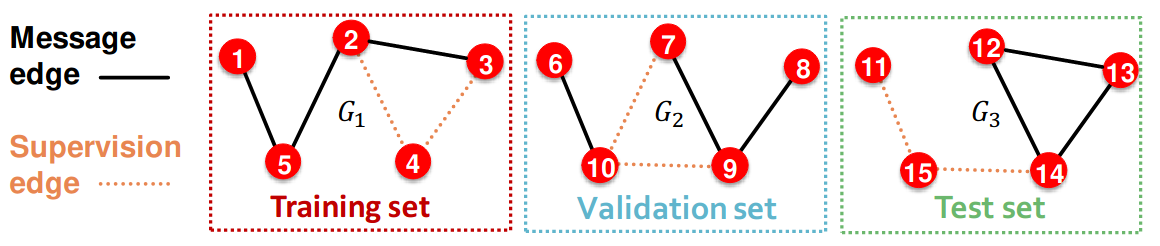
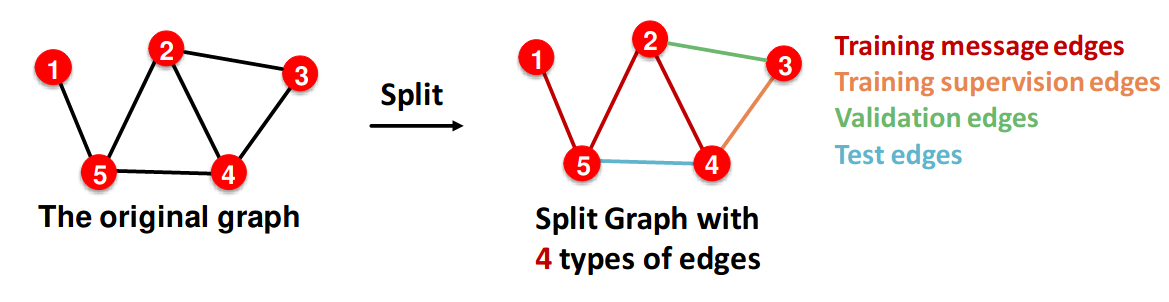
- transductive setting是链接预测的默认设置。在这种情况下,只有一个图,且在所有数据集划分中都是可见的。 | Stage | GNN输入 | 标签 | | ----- | ------------- | ----- | | 训练 | 训练消息边 | 训练监督边 | | 验证 | 训练消息/监督边 | 验证边 | | 测试 | 训练消息/监督边, 验证边 | 测试边 | 链接预测在PyG和GraphGym中完全支持。
6 图神经网络的理论基础¶
我们希望回答的问题是:图神经网络(GNNs)的表达能力到底有多强? 具体来说:如何设计一个表达能力最强的 GNN 模型? 设置 我们关注基于消息传递的 GNNs:
- 消息传递:每个节点计算一条消息
- 聚合:聚合来自邻居的消息
GNN 通过每个节点的邻域所导出的计算图来区分图结构。
- 如果两个节点的 k-hop 邻域结构相同,并且它们具有相同的特征,那么 GNN 将无法区分它们。
- 在下图中, 同色代表特征相同, 节点1和节点2在1-hop领域中都有一个degree=2和d=3的邻居; 2-hop邻域中都有d=2的节点4; 3-hop有d=1的节点3
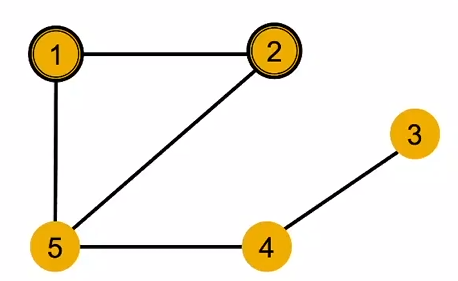
- 在下图中, 同色代表特征相同, 节点1和节点2在1-hop领域中都有一个degree=2和d=3的邻居; 2-hop邻域中都有d=2的节点4; 3-hop有d=1的节点3
- 计算子图是以每个节点为根的根状子树。
- 节点1和2计算图如下, 要注意的是, GNN只知道节点特征, 并不知道节点标号
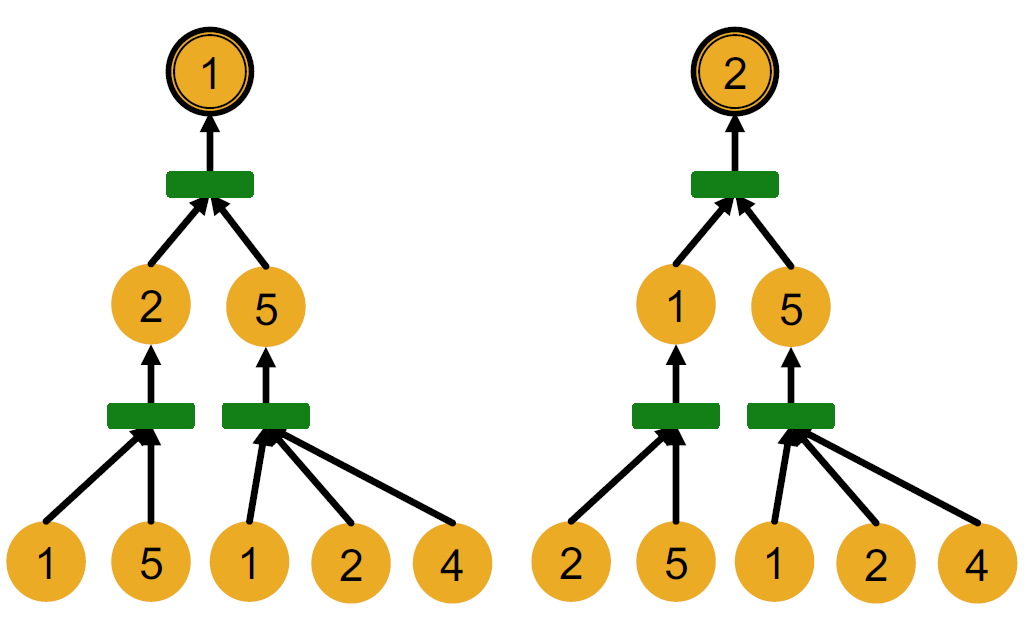 ->
->
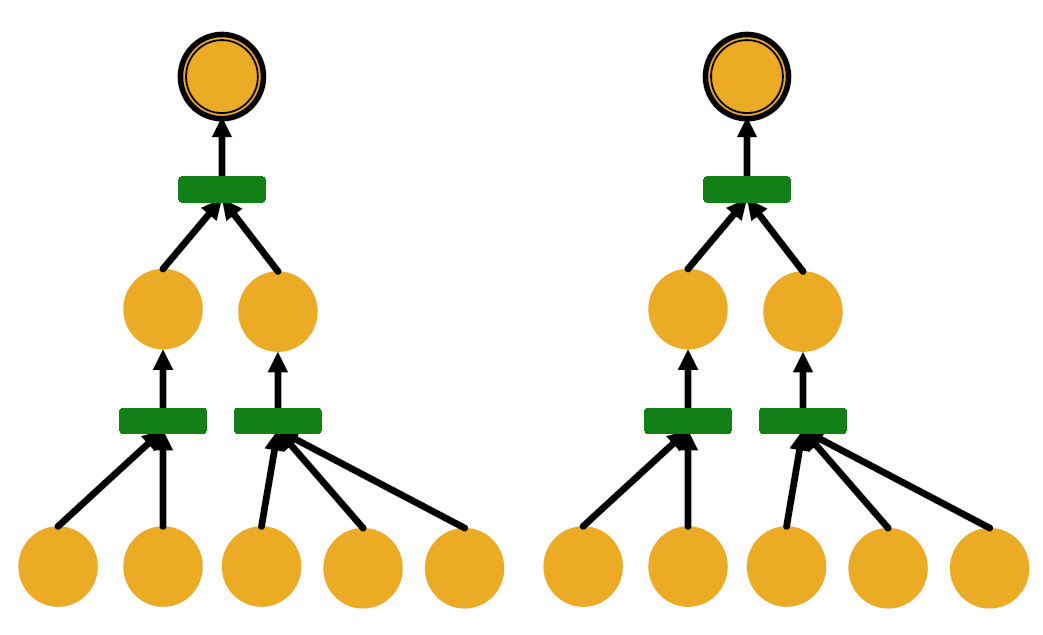
我们可以使用单射 (injections) 来衡量 GNN 的表达能力。
- 单射函数\(f: X\rightarrow Y\): 对于不同的输入, 一定会给出不同的输出 最具表达能力的 GNN 应该能够将子树单射地映射到节点结构上。
- 上面的例子就不是单射的, 将节点1和2映射到了相同的embedding
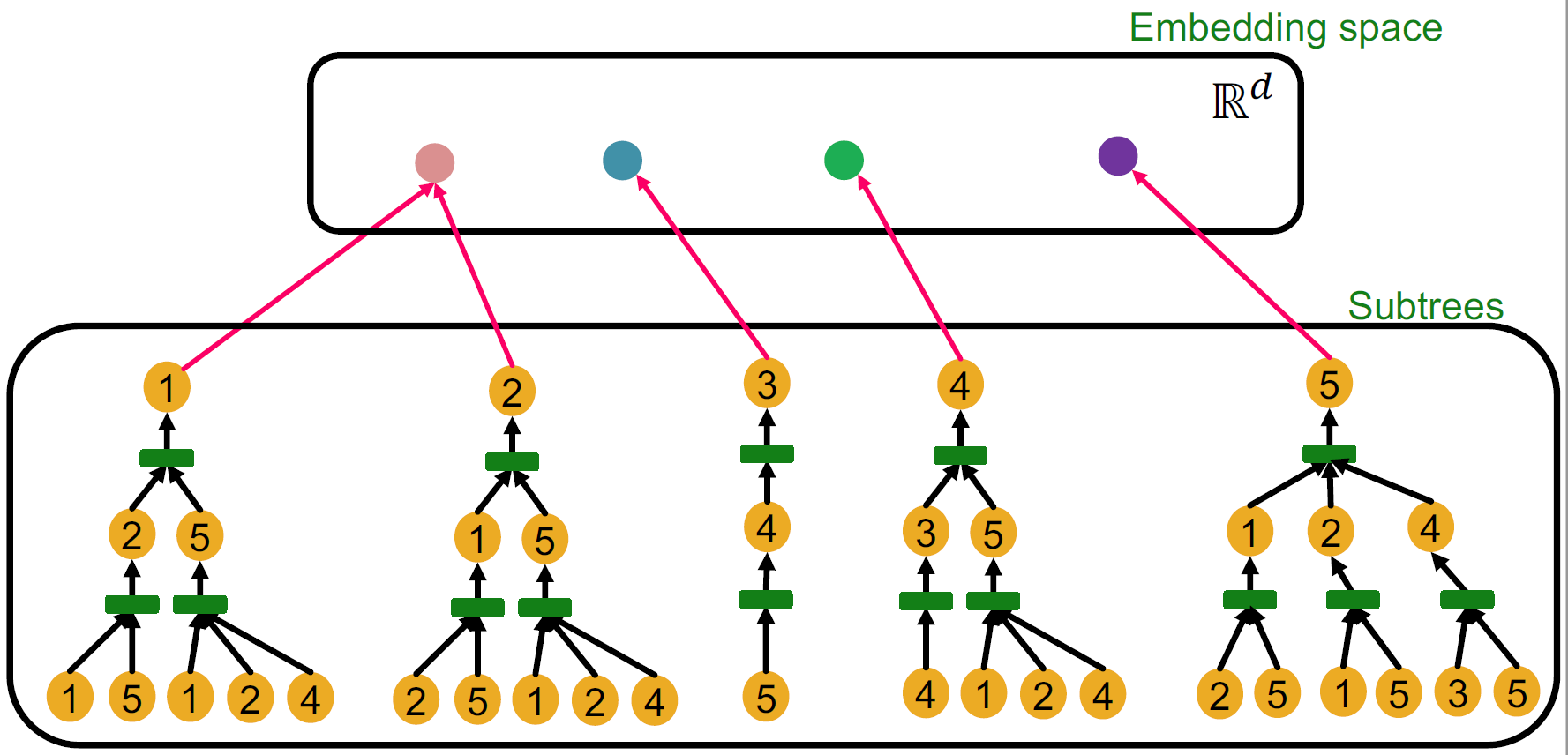 如果 GNN 的每一步聚合都能完全保留每个节点的邻域信息,那么生成的节点嵌入就能够区分不同的根状结构。
换句话说,最具表达能力的 GNN 采用单射的邻域聚合 (injective neighbourhood aggregation)。
如果 GNN 的每一步聚合都能完全保留每个节点的邻域信息,那么生成的节点嵌入就能够区分不同的根状结构。
换句话说,最具表达能力的 GNN 采用单射的邻域聚合 (injective neighbourhood aggregation)。
6.1 设计最具表达力的GNN¶
观察到GNN的表达能力可以由其使用的邻域聚合函数来表征。它可以被抽象为一个multi-set函数的操作: \(\text{Aggregate}(\{x_u : u \in \mathcal{N}(v)\})\)
在GCN中,这是均值函数(\(Mean(\{x_{u}\}_{u\in N(v)})\)),而在GraphSage中,这是最大池化函数(\(Max(\{x_{u}\}_{u\in N(v)})\))。例如,这两种池化函数都会在下面展示的邻居消息多集上创建相同的聚合: \(\left\{ \begin{bmatrix} 1 \\ 0 \end{bmatrix}, \begin{bmatrix} 0 \\ 1 \end{bmatrix} \right\}, \left\{ \begin{bmatrix} 1 \\ 0 \end{bmatrix}, \begin{bmatrix} 1 \\ 0 \end{bmatrix}, \begin{bmatrix} 0 \\ 1 \end{bmatrix}, \begin{bmatrix} 0 \\ 1 \end{bmatrix} \right\}\)
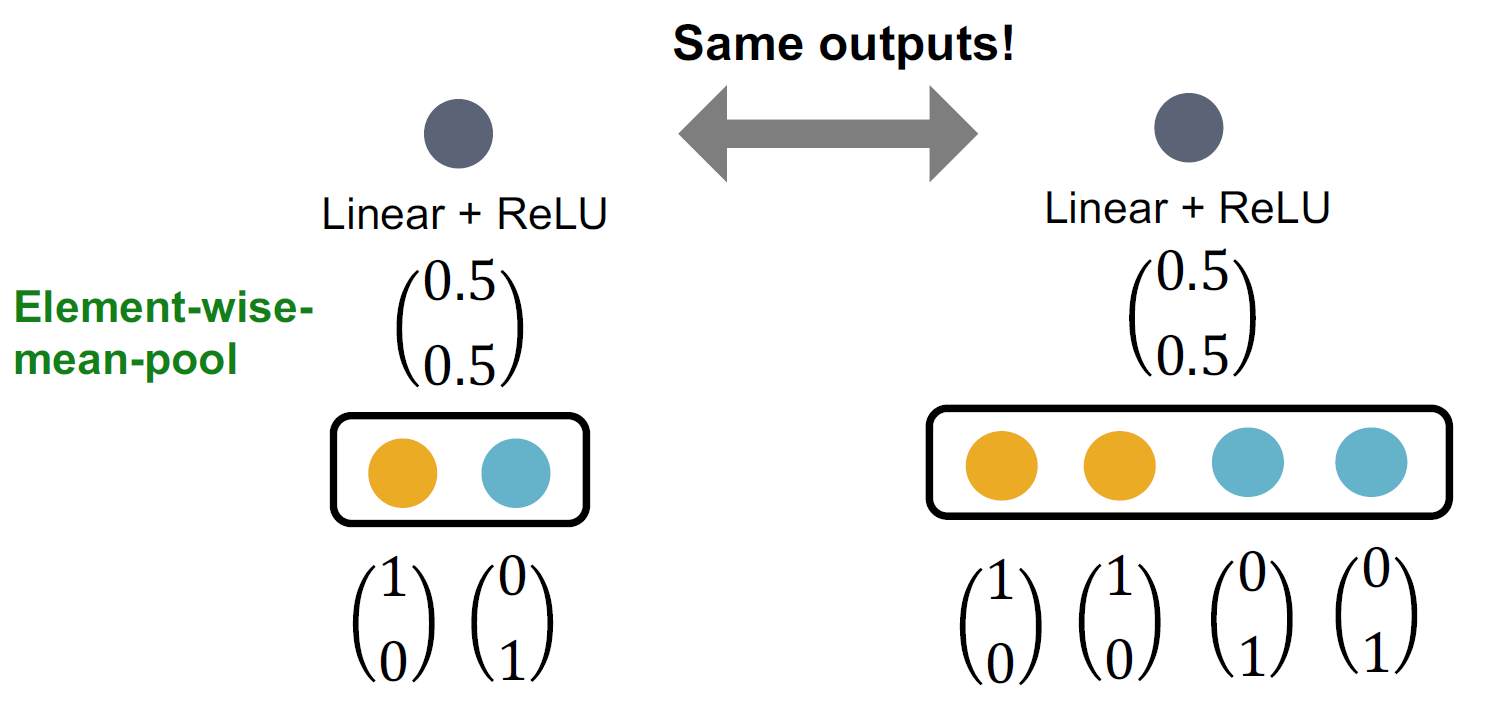
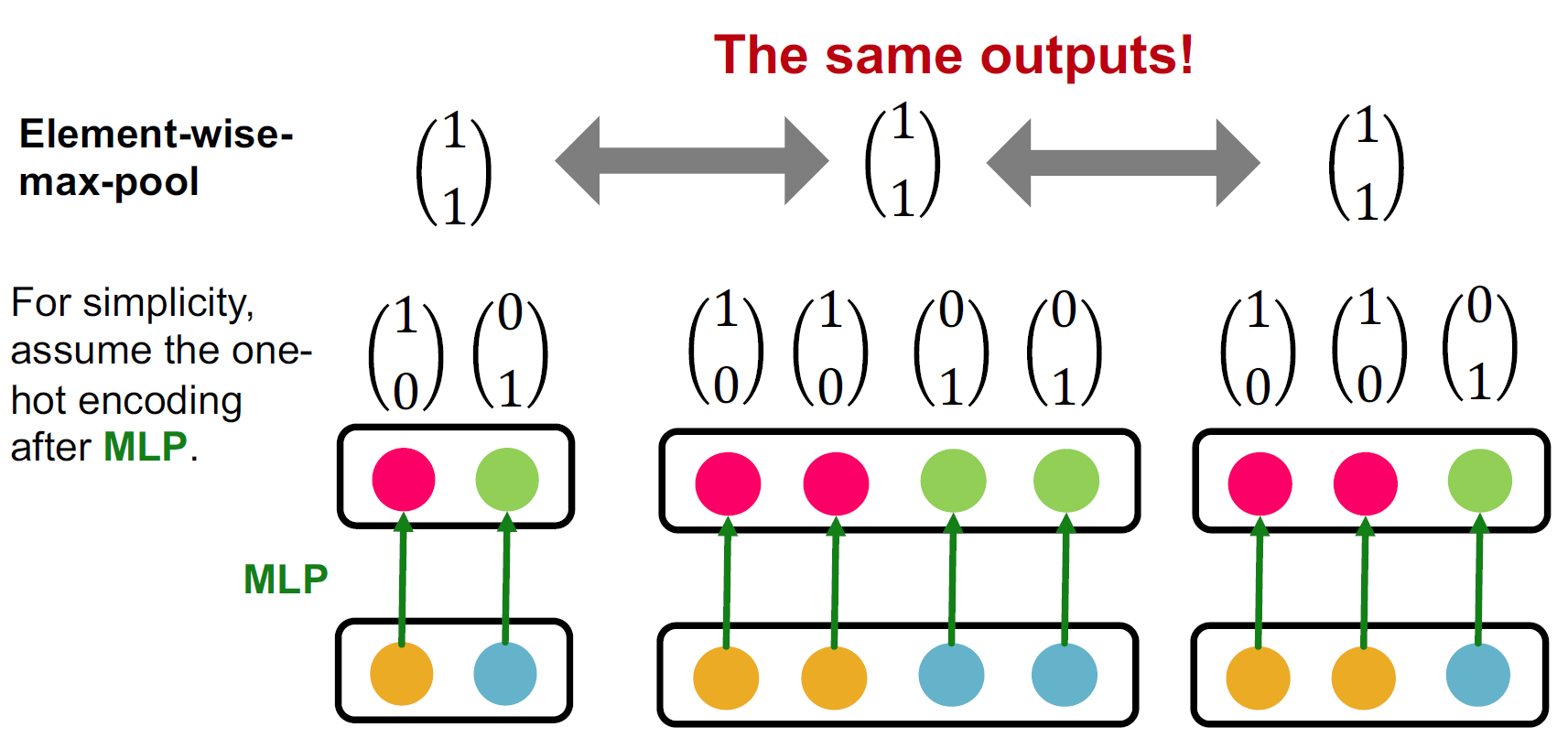
一般来说,判别能力的强弱顺序为: \(\text{求和(多重集)} > \text{均值(分布)} > \text{最大值(集合)}\)
定理6.1(Xu等人,ICLR 2019):任何单射多集函数都可以表示为: \(\phi\left(\sum_{x \in S} f(x)\right)\)
- 其中,\(\phi\)和\(f\)是非线性函数。
为了建模\(\phi\)和\(f\),我们可以使用多层感知机(MLP)。
定理6.2(通用近似定理,Hornik等人,1989):具有足够大隐藏层维度和非多项式激活函数\(\sigma\)的1隐藏层MLP可以任意精度地近似任何函数。
因此,我们可以使用以下结构来建模任何单射多集函数。通常,100到500的隐藏维度就足够了。这为我们带来了最具表达力的消息传递GNN:图同构网络(GIN)。 \(MLP_\phi \left(\sum_{x \in S} MLP_f(x)\right)\)
GIN使用上述的双MLP结构,它是最具表达力的消息传递GNN。
问题:为什么我们使用多集函数作为消息传递函数?
- 我们也可以使用哈希函数,但神经网络的好处是我们可以根据具体任务进行学习。
问题:我们是否可以为每个节点分配随机性以区分它们?
- 是的,但我们希望将相同的计算图映射到相同的输出。随机性会区分每个节点。
问题:为什么我们要将相同的邻域结构映射到相同的嵌入并忽略节点的个体身份?
- 在实际使用中,看到两个具有相同计算图的节点是非常罕见的。另一种架构,位置感知GNN,解决了这个问题。我们将在未来的讲座中看到它。
问题:为什么聚合函数应该是可学习的?为什么不能直接使用哈希函数代替MLP?
- 哈希函数确实非常表达力强。
- 使用神经网络的主要动机是:
- 每个节点都有特征。
- 神经网络是可微分的,可以与任务联合训练。
- 参数数量固定。
GIN与Weisfeiler-Lehman核(WL核)/颜色细化算法相当。给定一个图G,其节点为V:
- 为每个节点v分配一个初始颜色\(c^{(0)}(v)\)。
- 迭代地细化节点颜色: \(c^{(k+1)}(v) := \text{hash}(\{c^{(k)}(v)\} \cup \{c^{(k)}(u) | u \in \mathcal{N}(v)\})\)
- 经过k步颜色细化后,\(c^{(k)}\)总结了k阶邻域的结构。
WL核计算效率高。总时间复杂度为O(|E|)。其中,聚合函数是一个哈希函数。GIN使用神经网络建模WL核中的哈希函数。
定理6.3(Xu等人,ICLR 2019):任何对元组 \((c^{(k)}(v), \{c^{(k)}(u)\}_{u \in \mathcal{N}(v)})\) 的单射函数都可以建模为 \(\text{GINConv}(c^{(k)}(v), \{c^{(k)}(u) : u \in \mathcal{N}(v)\}) := \text{MLP}\phi\left( (1 + \epsilon)\text{MLP}f(c^{(k)}(v)) + \sum_{u \in \mathcal{N}(v)} \text{MLP}f(c^{(k)}(u)) \right)\)
问题:这里为什么需要\(\epsilon\)?
- 它允许区分节点本身与其邻居。
问题:在哈希表中,我们无法控制输出(几乎随机),但这里的情况似乎确定。为什么?
- 这里的讨论主要是关于如何设计多集上的注入函数。
GIN与WL核相比具有优势:
- 节点嵌入是低维的。因此,它们可以捕捉不同节点之间的细粒度相似性。
- 参数可以针对下游任务进行学习。
WL核在理论上和实证上都被证明可以区分大多数现实世界的图[Cai等人,1992]。因此,GIN也足够强大,可以区分大多数现实图。
6.2 当事情不按计划进行时¶
数据预处理非常重要!节点属性应该被归一化。
- 优化器:Adam对学习率相对鲁棒
- 激活函数:
- ReLU通常表现良好。
- 其他好的替代品:LeakyReLU、PReLU
- 输出层没有激活函数
- 每层都包含偏置
- 嵌入维度:32、64、128是良好的起点。
调试深度神经网络:
- 损失/准确率不收敛:
- 检查管道(例如,在PyTorch中需要将梯度归零)
- 调整超参数(如学习率)
- 注意权重参数初始化
- 仔细检查损失函数
- 对于模型开发非常重要:
- 在(部分)训练数据上过拟合。使用少量训练数据时,损失应该接近0,具有高表达力的神经网络。
- 监控训练和验证损失曲线。
20 扩展GNNs¶
20.0 前言¶
在现代应用中,图非常庞大。
- 在亚马逊/YouTube/Pinterest等推荐系统中,用户数量在108到109量级,产品/视频数量在107到109量级。
- 任务:推荐项目,对用户/项目进行分类
- 在Facebook/Twitter/Instagram等社交网络中,用户数量在108到109量级
- 任务:好友推荐,用户属性推荐
- 在Microsoft Academic Graph等学术图中
- 任务:论文分类,作者合作推荐,引用推荐
- 在Wikidata或Freebase等知识图中,实体数量约为10^8。
- 任务:知识图补全,推理
为什么训练GNN如此困难?¶
回归: 机器学习模型训练 在训练机器学习模型时,通常需要最小化平均损失: \(\ell(\theta) := \frac{1}{N} \sum_{i=0}^{N-1} \ell_i(\theta)\) 我们通过随机抽取大小为M≪N的批次B,计算B上的损失\(\hat{\ell}(\theta)\),并使用\(\theta \leftarrow \theta - \alpha \nabla \hat{\ell}(\theta)\)进行更新。
简单地全批次处理会迭代整个图的GCN层: \(H^{(k+1)} := \sigma \left( \tilde{A} H^{(k)} W_{K}^T + H^{(k)} B_{K}^T \right)\) 在大型图中这是不可行的,因为GPU内存极其有限(10-20 GB)。
我们介绍三种扩展GNN的方法。
- 两种方法采样较小的子图:Neighbor Sampling和Cluster GCN
- 一种方法将GNN简化为特征预处理操作:Simplified GCN
20.1 邻居采样¶
回顾一下,GNNs通过邻居聚合生成节点嵌入。为了计算单个节点n的嵌入,我们只需要其K-hop邻域。我们可以采样M≪N个节点,构建它们的K阶邻域,并使用生成的计算图训练GNN。
这种方法的问题在于K阶邻域的大小可能呈指数增长,尤其是在遇到hub node(高度节点)时。在邻居采样中,每个hop仅在第k层采样最多\(H_k\)个邻居。然后我们使用修剪后的计算图训练GNN。一个K层GNN将涉及最多\(∑_{k=1}^K H_k\)个叶节点在计算图中。
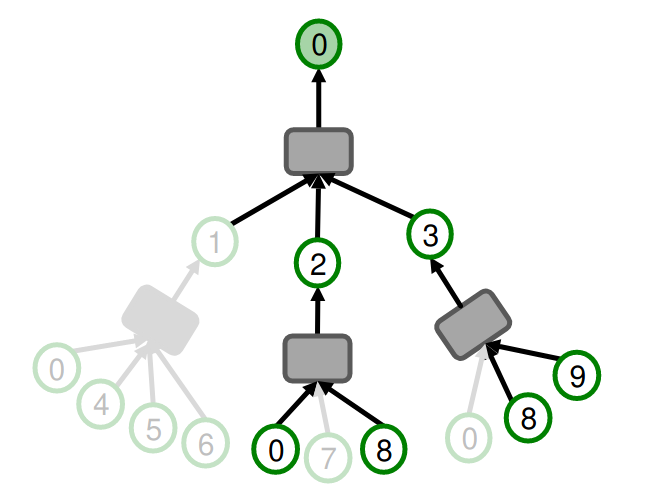 例: H=2
例: H=2
好处和缺点
- H是聚合效率和方差之间的权衡。较小的H导致更高效的计算,但会增加方差,从而导致训练结果不稳定。
- 计算图的大小仍然随K呈指数增长。每多一层GNN,计算成本会增加H倍。
邻居可以随机采样,这很快,但可能不是最优的。在自然图中,我们可以使用带有重启的随机游走,并采样重启分数最高的节点。这在实践中效果更好。 总体时间复杂度:\(M · H^K\)。
20.2 Cluster GCN¶
回顾: Full Batch GNN¶
观察: 到当节点共享许多层时,计算这些邻居的嵌入会变得冗余。
- 在Full Batch GNN中,只需要计算\(2|E_M|\)(其中\(E_M\)是边消息的集合)条消息,并且在K层GNN中总体只需要计算\(2K|E_K|\)条消息。
- 逐层节点嵌入更新允许重复使用前一层的嵌入。
- 但是逐层更新在大型图中不可行,因为GPU内存有限。
Cluster-GCN子图采样¶
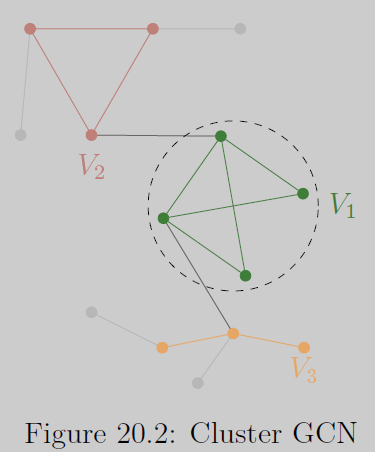
在Cluster-GCN中,我们可以采样大型原始图的一个小社区,并在较小的图中高效地进行逐层节点嵌入更新。 什么子图适合训练GNNs?
- 由于GNNs沿边传递消息,子图应尽可能保留原始图的连通性。
- 真实世界图具有社区结构,我们可以采样一个社区作为子图,每个社区保留基本的连接模式。
Cluster-GCN训练流程¶
- 预处理:给定一个大型图,将其节点分区
- 使用社区检测算法(如Louvain、METIS)将大型图G=(V,E)的节点V分区为C组V1,...,VC。每个节点组Vi导出一个子图Gi。
- 注意,在G中的组间边会被丢弃。
- 小批次训练:一次采样节点组Vi,并在节点组Gi上应用GNN。
这种方法的问题在于:
- 组间边被丢弃: 这会导致系统性偏差的梯度估计。
- 采样的节点组往往只覆盖整个数据的一小部分。
- 采样的节点不够多样化,无法代表整个图的结构: 这会导致不同批次之间的梯度差异很大,从而导致SGD的收敛速度变慢。
解决方案是Advanced Cluster-GCN:在每个小批次中聚合多个节点组。
- 预处理:给定一个大型图,将其节点分区
- 使用社区检测算法将大型图G=(V,E)的节点V分区为C组V1,...,VC。它们必须足够小,以便多个节点组可以同时加载到GPU中。
- 小批次训练:采样节点组Vi1,...,Viq,并在Vi1∪···∪Viq induce的图上应用GNN。
总体时间复杂度为Cluster-GCN:\(K·M·D_{avg}\),其中Davg是平均节点度。这种线性增长比邻居采样高效得多。
一些问题¶
Question: 对于没有社区的节点怎么办?
可以将孤立节点分配到某个社区中。
Question: 可以在不同的子图上训练不同的模型吗?
最好训练一个统一的模型,以防止模型在某个子图上过拟合。
Question: 诱导子图会导致子图之间的连接丢失。我们可以将诱导子图视为超节点 (hypernode) 吗?
这是一个有趣的研究问题。目前尚不清楚是否可以用一个超节点来表示整个子图。
可以参考 GNNAutoScale。
Question: 选择大量小社区 vs. 选择少量大社区,在计算上的权衡是否值得?
是的。许多社区选择算法的复杂度是 O(|V|),即与节点数 |V| 线性相关。
Question: Cluster-GCN 是否可以轻松适配到异构图 (heterogeneous graphs)?
这可能会对不同类型的边引入偏差。这是一个值得研究的问题。
20.3 Simplified GCN¶
我们从GCN开始。回顾一下,GCN聚合函数的形式是\(E^{(k+1)} := ReLU(\tilde{A}E^{(k)}W^{(k)})\)。
Simplified GCN在邻接矩阵A上使用自环:\(A ← A + I\)。它还假设节点嵌入\(E\)由特征给出。这些是与LightGCN的主要区别。 由于节点特征是固定的,矩阵\(\tilde{E} := \tilde{A}^KE\)可以仅作为预处理步骤计算一次。\(\tilde{E}\)已经具有非常丰富的特征,可以输入到现有的机器学习模型中。
尽管表达能力较弱,简化GCN在许多节点分类任务中表现与原始GNN相当。其原因是许多节点分类任务中的同质性,即通过边连接的节点往往共享相同的标签。因此,通过边连接的节点往往具有相似的预处理特征。这是由于嵌入空间的高维性。
Question: 由于我们移除了激活函数,但性能仍然很强,这是否意味着我们学习到的很多内容是线性的?
是的。
备注: 不是很理解 之后再补一下https://www.bilibili.com/video/BV1vD4rePEiP