Homework Notes
overall¶
colab导入库问题¶
引用挂载的needle库时, 修改了needle库文件内容后, 还需要重新导入
plan a: 启用autoreload, 设置为模式1: 在每次执行cell前, reload用 %aimport 标记过的模块
或者plan b: 设置为模式2: 在每次执行cell前, reload所有已导入模块
注: 重复导入可能会造成一些奇怪的bug, 可以尝试重启运行时
- bug例: 重复导入ndl库, 导致isinstance(ndl.Tensor, ndl.autograd.Tensor)结果为False ...非常抽象
Jupyter小技巧¶
使用clear_output来清空上一条命令
!make -j32
from IPython.display import clear_output
clear_output(wait=True)
!python3 -m pytest -v -s -k "(compact or setitem) and cpu"
Homework1¶
运算¶
Broadcast¶
def broadcast_to(a, shape): broadcast an array to a new shape (1 input, shape - tuple)
广播, 复制张量的某些维度, 使得不同形状的数组进行逐元素运算时更加方便
- 向量加标量:把标量加到每个元素。
- 矩阵加列向量:把列向量加到矩阵每一列。
- 矩阵乘以标量:标量自动扩展到矩阵大小。
广播的梯度计算: 沿着广播的维度sum回去 - 广播的本质是变量复制, 广播后的元素参与了多次的计算, 反向传播时要累加这部分的梯度值
Homework2¶
初始化方法选择¶
Linear初始化要选择kaiming_uniform, 否则无法通过测试
L2正则化+动量SGD更新公式¶
TypeError: Module.__init__() takes 1 positional argument but 2 were given¶
def forward(self, x: Tensor) -> Tensor:
### BEGIN YOUR SOLUTION
res = x
for module in self.modules:
> res = module(res)
^^^^^^^^^^^
E TypeError: Module.__init__() takes 1 positional argument but 2 were given
nn.ReLU()误写为nn.ReLU
- 类型检查没做好...
AssertionError: float64 float32`¶
NOTE: The default data type for the tensor is
float32. If you want to change the data type, you can do so by setting thedtypeparameter in theTensorconstructor. For example,Tensor([1, 2, 3], dtype='float64')will create a tensor withfloat64data type. In this homework, make sure any tensor you create hasfloat32data type to avoid any issues with the autograder.
在optimizer中, 会使用float64的超参数乘以float32的tensor, 最终导致整个值变为float64, 此时重新复制给data, 就会引发AssertionError: float64 float32
注: 此为Tensor类方法中的断言
class Tensor(Value):
@data.setter
def data(self, value):
assert isinstance(value, Tensor)
assert value.dtype == self.dtype, "%s %s" % (
value.dtype,
self.dtype,
)
self.cached_data = value.realize_cached_data()
过了!
 备注: 训练OOM, 被kill掉了
备注: 训练OOM, 被kill掉了
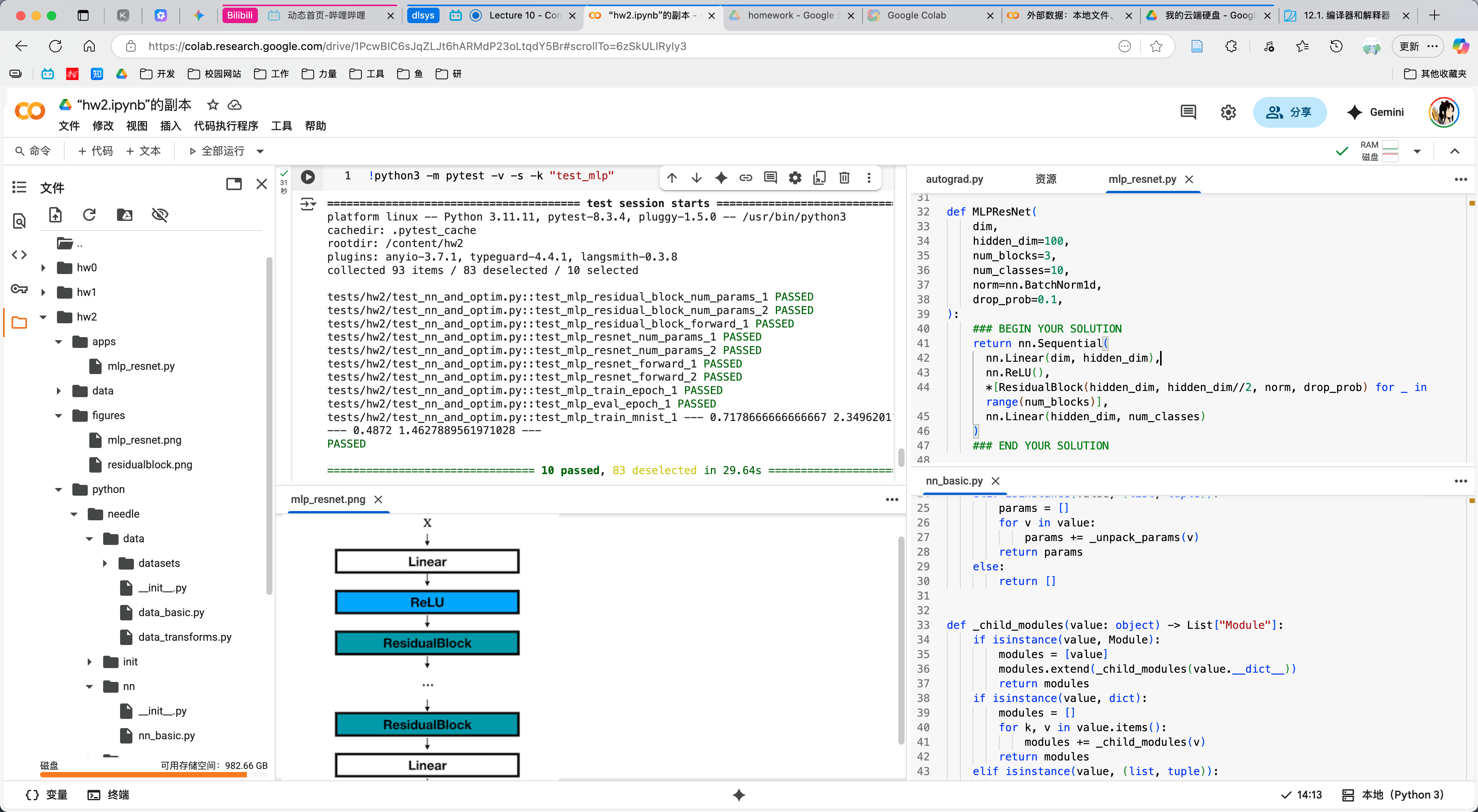
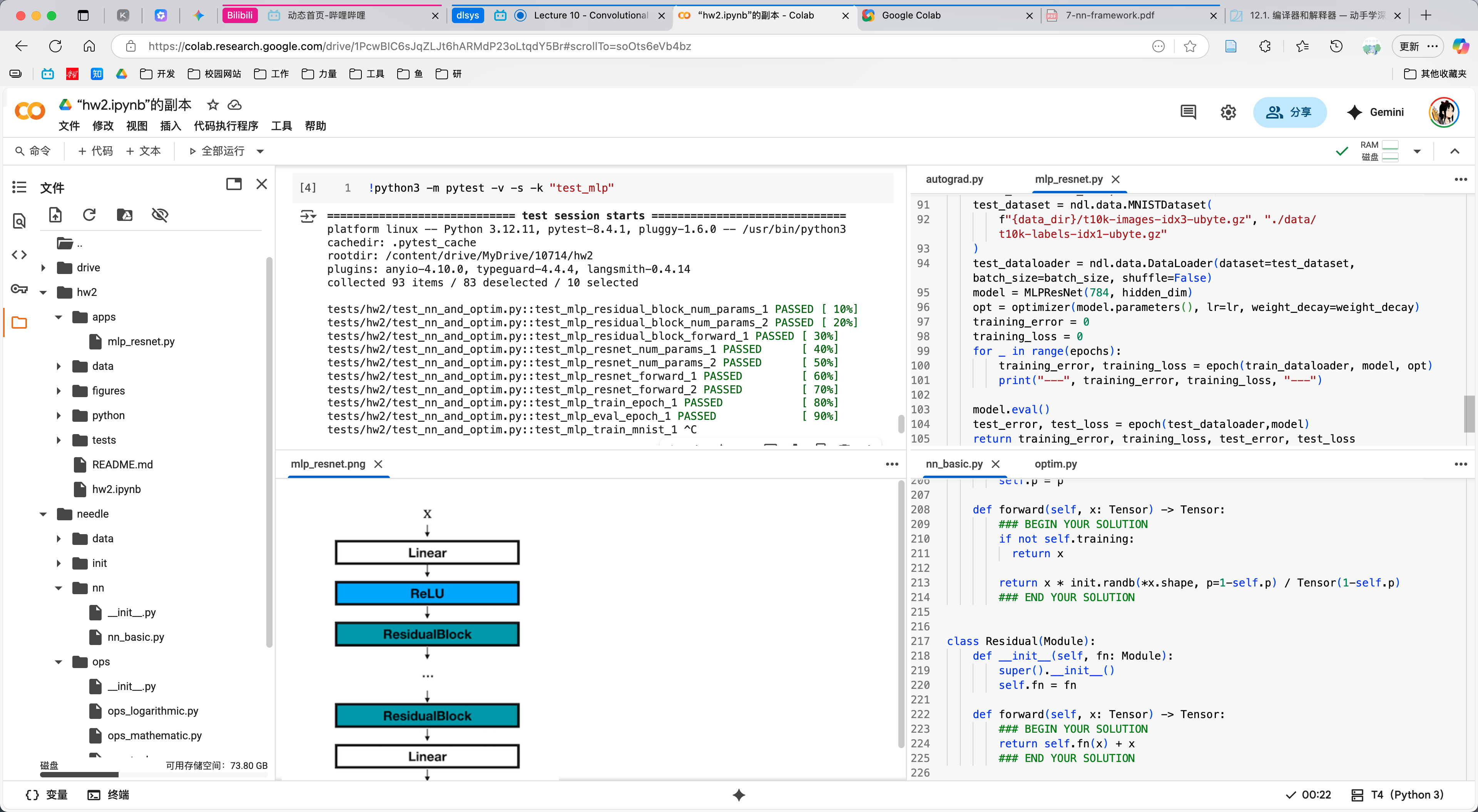
Homework3¶
如何直接计算noncompact->compact的映射关系¶
__global__ void CompactKernel(const scalar_t *a, scalar_t *out, size_t size, CudaVec shape,
CudaVec strides, size_t offset)
{
/**
* The CUDA kernel for the compact opeation. This should effectively map a single entry in the
* non-compact input a, to the corresponding item (at location gid) in the compact array out.
*
* Args:
* a: CUDA pointer to a array
* out: CUDA point to out array
* size: size of out array
* shape: vector of shapes of a and out arrays (of type CudaVec, for past passing to CUDA kernel)
* strides: vector of strides of out array
* offset: offset of out array
*/
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
/// BEGIN SOLUTION
// assert(false && "Not Implemented");
if (gid >= size)
return;
size_t a_idx = offset;
size_t tmp = gid;
for (size_t i = shape.size; i > 0; i--)
{
// 计算当前维度的索引
size_t dim_idx = tmp % shape.data[i - 1];
// 计算基于步长的映射, 并累加
a_idx += dim_idx * strides.data[i - 1];
tmp /= shape.data[i - 1];
}
out[gid] = a[a_idx];
/// END SOLUTION
}
Compact & Setitem¶
void Compact(const AlignedArray &a, AlignedArray *out, std::vector<int32_t> shape, std::vector<int32_t> strides, size_t offset){
/**
* Compact an array in memory
*
* Args:
* a: *non-compact* representation of the array, given as input
* out: compact version of the array to be written
* shape: shapes of each dimension for a and out
* strides: strides of the *a* array (not out, which has compact strides)
* offset: offset of the *a* array (not out, which has zero offset, being compact)
*
* Returns:
* void (you need to modify out directly, rather than returning anything; this is true for all the
* function will implement here, so we won't repeat this note.)
*/
}
void EwiseSetitem(const AlignedArray &a, AlignedArray *out, std::vector<int32_t> shape, std::vector<int32_t> strides, size_t offset){
/**
* Set items in a (non-compact) array
*
* Args:
* a: **_compact_** array whose items will be written to out
* out: non-compact array whose items are to be written
* shape: shapes of each dimension for a and out
* strides: strides of the *out* array (not a, which has compact strides)
* offset: offset of the *out* array (not a, which has zero offset, being compact)
*/
}